

一、倒排索引¶
面试题: 分片底层时如何工作的?
答: 分片底层对应的是一个Lucene库,而Lucene底层使用倒排索引技术实现。
正排索引(正向索引):
我们MySQL为例,用id字段存储博客文章的编号,用context存储文件的内容。
CREATE TABLE blog (id INT PRIMARY KEY AUTO_INCREMENT, context TEXT);
INSERT INTO blog VALUES (1,'I am Jason Yin, I love Linux ...')
此时,如果我们查询文章内容包含"Jason Yin"的词汇的时候,就比较麻烦了,因为要进行全表扫描。
| SELECT * FROM blog WHERE context LIKE 'Jason Yin'; |
|---|
倒排索引(反向索引)
ES使用一种称为"倒排索引"的结构,它适用于快速的全文检索。
倒排索引中有以下三个专业术语:
-
词条: 指的是最小的存储和查询单元,换句话说,指的是您想要查询的关键字(词)。对应英文而言通常指的是一个单词,而对于中文而言,对应的是一个词组。
-
词典(字典):它是词条的集合,底层通常基于"Btree+"和"HASHMap"实现。
-
倒排表:记录了词条出现在什么位置,出现的频率是什么。倒排表中的每一条记录我们称为倒排项。
倒排索引的搜索过程:
(1) 首先根据用户需要查询的词条进行分词后,将分词后的各个词条字典进行匹配,验证词条在词典中是否存在;
(2) 如果上一步搜索结果发现词条不在字典中,则结束本次搜索,如果在词典中,就需要去查看倒排表中的记录(倒排项);
(3) 根据倒排表中记录的倒排项来定位数据在哪个文档中存在,而后根据这些文档的"_id"来获取指定的数据;
综上所述,假设有10亿篇文章,对于mysql不创建索引的情况下,会进行全表扫描搜索"Jason Yin"。而对于ES而言,其只需要将倒排表中返回的id进行扫描即可,而无须进行全量查询。
二、集群角色¶
查看node角色
[root@elk121 ~]# curl 192.168.1.121:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.1.121 52 23 0 0.02 0.10 0.05 cdfhilmrstw - elk121
192.168.1.123 51 30 0 0.07 0.29 0.15 cdfhilmrstw - elk123
192.168.1.122 48 24 0 0.03 0.14 0.07 cdfhilmrstw * elk122

角色说明
| 角色 | 角色说明 |
|---|---|
| c | Cold data(冷数据) |
| d | data node(数据节点) |
| f | frozen node(冻结节点) |
| h | hot node(热节点) |
| i | ingest node(摄取节点) |
| l | machine learning node(机器学习节点) |
| m | master eligible node(主节点候选节点) |
| r | remote cluster client node(远程集群客户端节点) |
| s | content node(内容节点) |
| t | transform node(转换节点) |
| v | voting-only node(仅投票节点) |
| w | warm node(温暖节点) |
| - | coordinating node only(仅协调节点) |
常见角色说明
<colgroup> <col style="width: 50%" /> <col style="width: 50%" /> </colgroup>| 角色 | 角色说明 |
|---|---|
| data node | 指的是存储数据的节点 node.data: true |
| master node | 控制ES集群,并维护集群的状态(cluster state,包括节点信息,索引信息等,ES集群每个节点都有一份)。 node.master: true |
| coordinating | 协调节点可以处理请求的节点,ES集群所有的节点均为协调节点,该角色无法取消。 |
三、master角色和data角色分离实战¶
1、停止所有节点的ES服务
[root@elk121 ~]# systemctl stop es7
[root@elk122~]# systemctl stop es7
[root@elk123~]# systemctl stop es7
2、所有节点清空数据(仅用于刚开始搭建集群时使用)
[root@elk121 ~]# rm -rf /es/{data,logs}/es7/* /tmp/*
[root@elk122~]# rm -rf /es/{data,logs}/es7/* /tmp/*
[root@elk123~]# rm -rf /es/{data,logs}/es7/* /tmp/*
3、所有修改配置文件
(1)在elk121节点上修改配置文件
[root@elk121 ~]# vim /es/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
…
…
cluster.initial_master_nodes: ["elk123"]
node.data: true
node.master: false
修改后的配置文件内容如下
[root@elk121 ~]# egrep -v '^$|^#' /es/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
cluster.name: es
path.data: /es/data/es7
path.logs: /es/logs/es7
network.host: 192.168.1.121
discovery.seed_hosts: ["elk121","elk122","elk123"]
cluster.initial_master_nodes: ["elk123"]
reindex.remote.whitelist: "192.168.1.*:19200"
node.data: true
node.master: false
(2)在elk122节点上修改配置文件
[root@elk122~]# vim /es/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
…
…
cluster.initial_master_nodes: ["elk123"]
node.data: true
node.master: false
修改后的配置文件内容如下
[root@elk122 ~]# egrep -v '^$|^#' /es/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
cluster.name: es
path.data: /es/data/es7
path.logs: /es/logs/es7
network.host: 192.168.1.122
discovery.seed_hosts: ["elk121","elk122","elk123"]
cluster.initial_master_nodes: ["elk123"]
reindex.remote.whitelist: "192.168.1.*:19200"
node.data: true
node.master: false
(3)在elk123节点上修改配置文件
[root@elk123~]# vim /es/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
…
…
cluster.initial_master_nodes: ["elk123"]
node.data: false
node.master: true
修改后的配置文件内容如下
[root@elk123 ~]# egrep -v '^$|^#' /es/softwares/es7/elasticsearch-7.17.5/config/elasticsearch.yml
cluster.name: es
path.data: /es/data/es7
path.logs: /es/logs/es7
network.host: 192.168.1.123
discovery.seed_hosts: ["elk121","elk122","elk123"]
cluster.initial_master_nodes: ["elk123"]
reindex.remote.whitelist: "192.168.1.*:19200"
node.data: false
node.master: true
4、启动集群
[root@elk121 ~]# systemctl start es7
[root@elk122 ~]# systemctl start es7
[root@elk123 ~]# systemctl start es7
5、验证配置
[root@elk121 ~]# curl 192.168.1.121:9200/_cat/nodes
192.168.1.121 55 22 1 0.22 0.08 0.06 cdfhilrstw - elk121
192.168.1.122 49 22 1 0.22 0.10 0.07 cdfhilrstw - elk122
192.168.1.123 46 29 0 0.08 0.07 0.06 ilmr * elk123
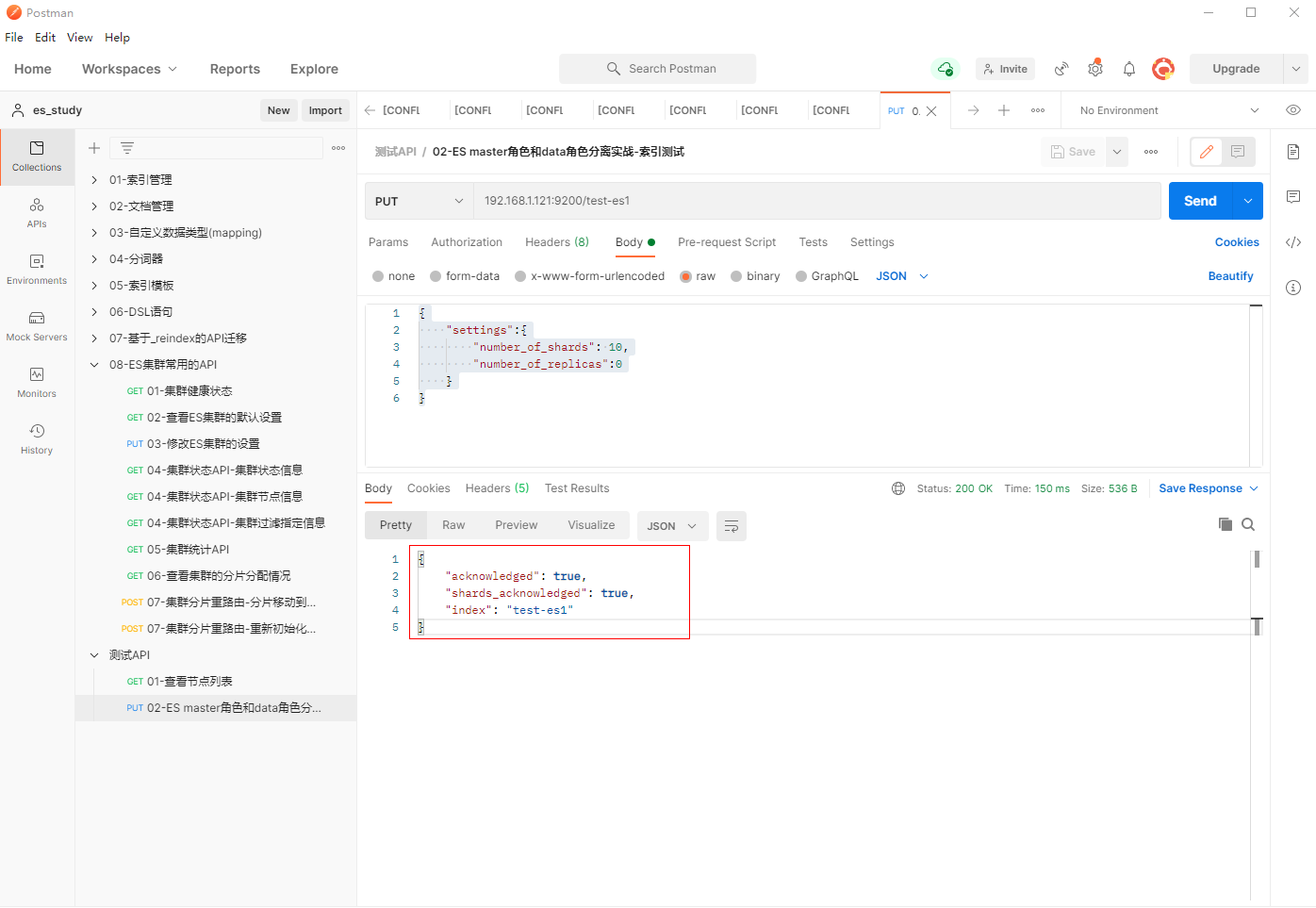
6、创建索引测试,观察elk123是否能够存储分片。
填写PUT请求192.168.1.121:9200/test-es1,创建10分片0副本的索引test-es1
{
"settings":{
"number_of_shards": 10,
"number_of_replicas":0
}
}
四、ES文档的写入流程图解¶
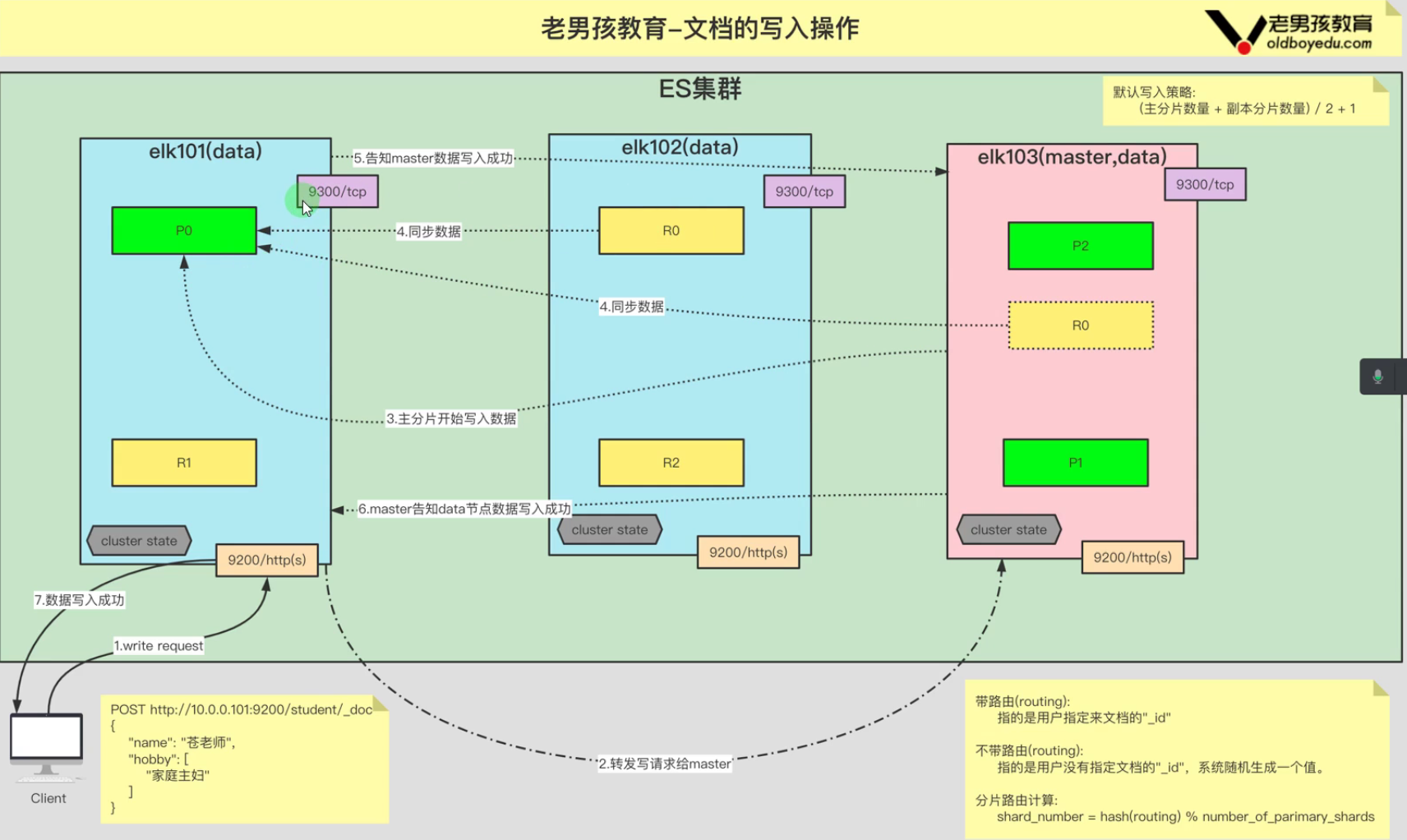
1、客户端提交post请求到协调节点的9200端口
2、当写入请求到达协调节点时,如果没有提供文档ID,协调节点将负责生成一个唯一的ID,并将其分配给文档。并转发请求给Master节点
3、主节点根据写入请求中指定的索引名称来确定带没带路由(指定文档的_id)。如果带路由,使用文档ID(或生成的文档ID)和索引的信息,通过哈希算法等方式确定文档应该被分配到哪个分片中; 如果不带路由,主节点会随机生成一个唯一的文档ID,然后使用文档ID(或生成的文档ID)和索引的信息,通过哈希算法等方式确定文档应该被分配到哪个分片中
4、一旦路由判断完成,主节点将写入请求转发给负责该分片的数据节点。数据节点执行具体的写入操作
5、如果配置了分片的副本(replicas),主节点会将写入操作同步到相应数量的副本分片中。
6、当数据节点写入数据成功后,会告知主节点数据写入成功
7、主节点通知协调节点写入成功
8、协调节点将这个确认返回给客户端
五、ES文档的读取流程图解¶
5.1 单个文档的读取操作图解¶
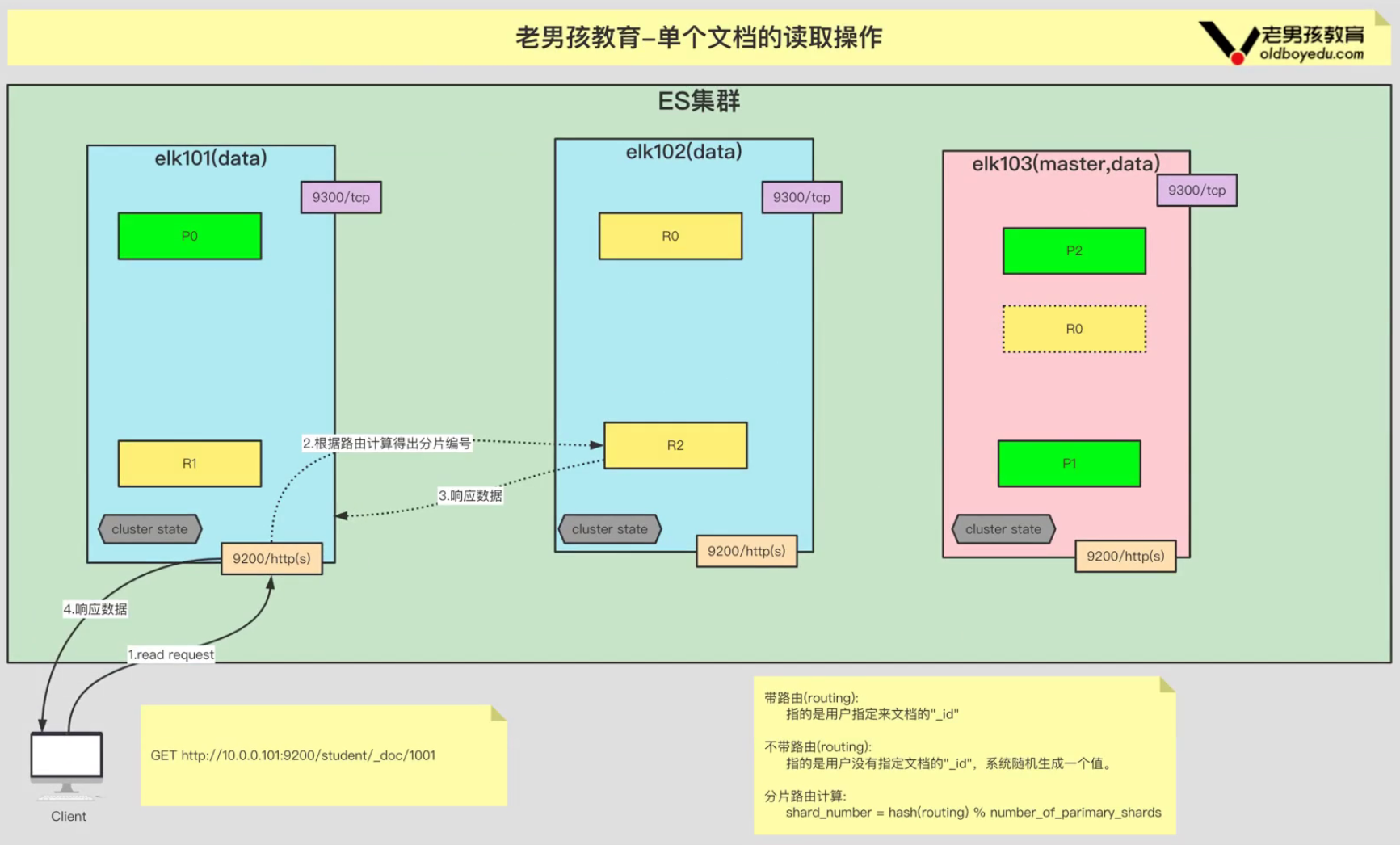
1、客户端发送10.0.0.101:9200/student/_doc/1001请求
2、协调节点分析URL,提取出索引名为 student,文档ID为 1001。并转发读取请求给主节点
3、主节点接收到这个读取请求后,会进行路由操作,确定文档ID 1001 属于索引 student 的哪个分片。
4、主节点将读取请求路由到负责 student 索引、包含文档ID 1001 的分片上
5、数据节点,即负责该分片的节点,会在本地存储中查找文档ID为 1001 的文档。
6、如果文档存在,数据节点将文档数据返回给主节点;如果不存在,返回404Not Found响应
7、主节点将从数据节点接收到的文档数据或错误信息返回给发起读取请求的客户端
5.2 文档的全量查询图解¶
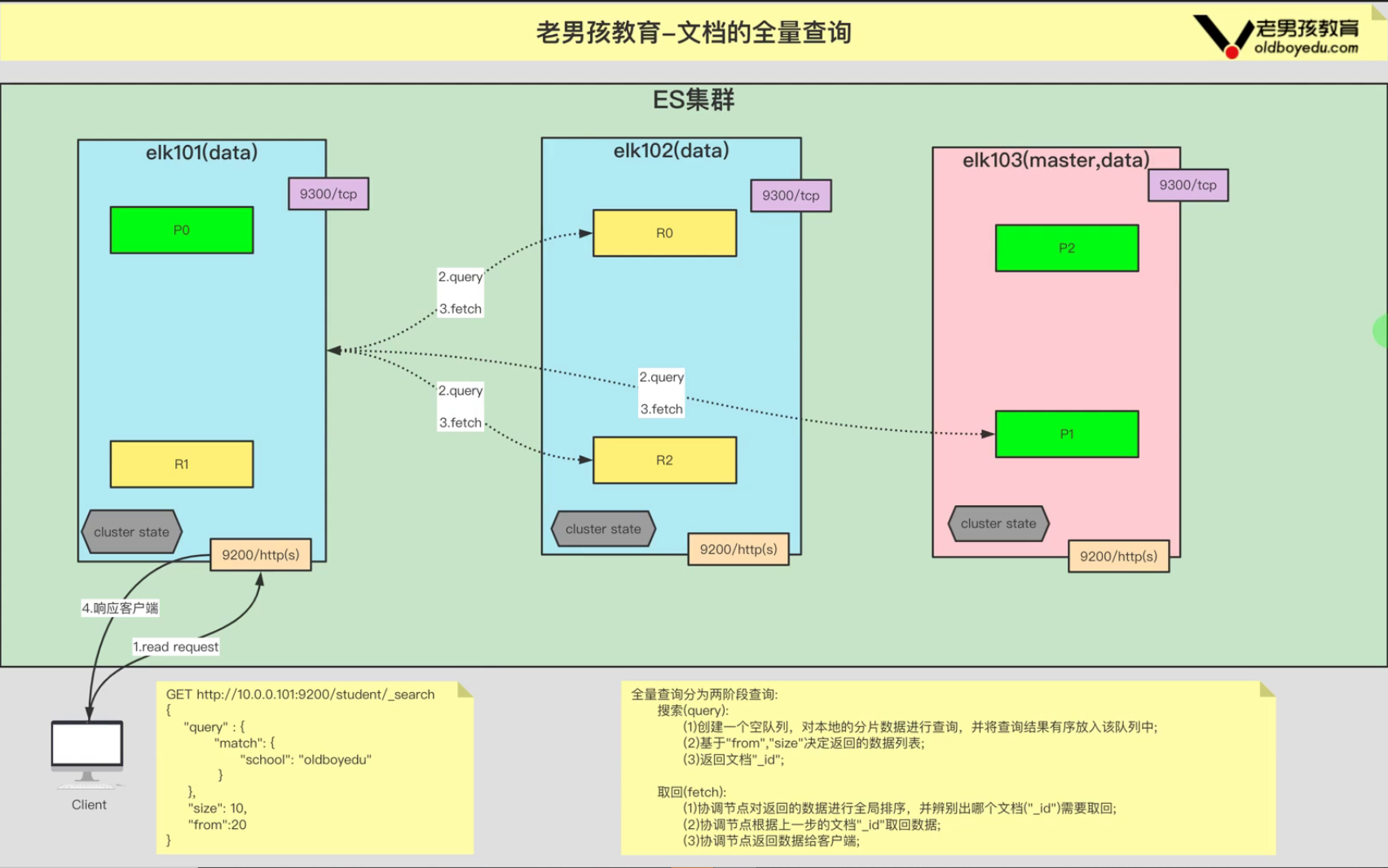
1、客户端发送文档全量查询请求,在这个情况下,请求中通常只包含索引名称,而没有指定特定的文档ID。
2、主节点接收到查询请求后,根据索引名称进行路由,确定请求涉及哪个索引。
3、主节点协调查询请求,并将查询请求发送到每个包含索引数据的分片。
4、每个数据节点负责执行本地的查询操作,检索包含在它管理的分片中的文档。数据节点将其本地的查询结果返回给主节点。
5、主节点收到各个数据节点的查询结果后,会将这些结果进行合并,形成最终的全量查询结果。这个合并可能包括去重、排序等操作,具体取决于查询的要求。
6、最终的全量查询结果将由主节点返回给发起查询请求的客户端。客户端可以根据这些结果进行进一步的处理和分析。
六、ES底层存储原理剖析¶
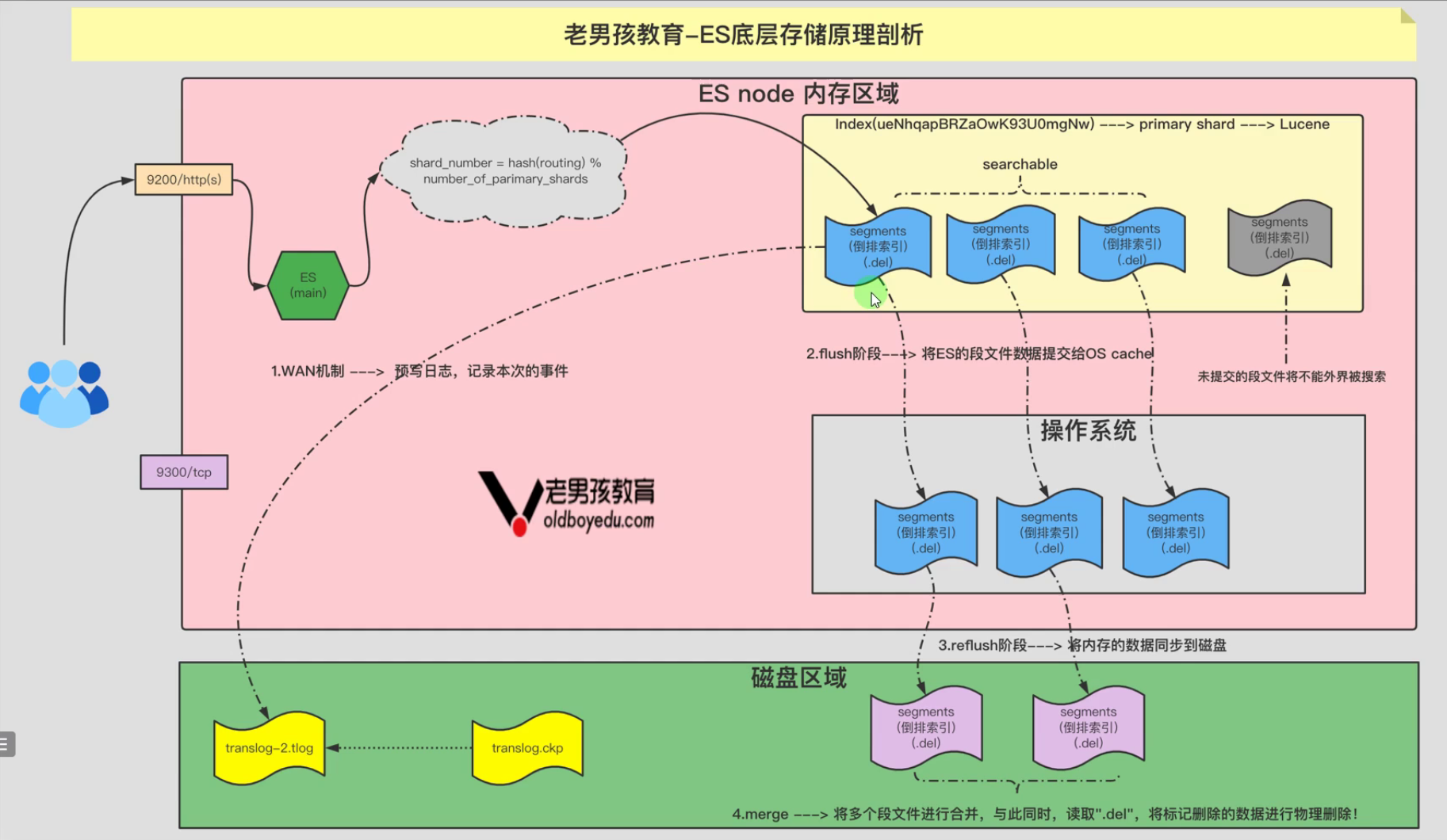
1、客户端发送写入请求后
2、WAL机制:预写日志,记录本次的事件
3、flush阶段: 将ES的段文件数据提交给OS cache
4、reflush阶段: 将内存的数据同步到磁盘
5、merge阶段:将多个段文件进行合并,与此同时,读取".d",将标记删除的数据进行物理删除!