一、Pod探针基础¶
1.1 Pod的三种探针¶
| 种类 | 说明 |
|---|---|
| startupProbe | Kubernetes1.16 新加的探测方式,用于判断容器内的应用程序是否已经启动。如果 配置了startupProbe,就会先禁用其他探测,直到它成功为止。如果探测失败,Kubelet 会杀死容器,之后根据重启策略进行处理,如果探测成功,或没有配置 startupProbe, 则状态为成功,之后就不再探测。 |
| livenessProbe | 用于探测容器是否在运行,如果探测失败,kubelet 会“杀死”容器并根据重启策略 进行相应的处理。如果未指定该探针,将默认为 Success |
| readinessProbe | 一般用于探测容器内的程序是否健康,即判断容器是否为就绪(Ready)状态。如果是,则可以处理请求,反之 Endpoints Controller 将从所有的 Service 的 Endpoints 中删除此容器所在Pod的IP地址。如果未指定,将默认为Success |
livenessProbe和startupProbe二者区别
- startupProbe只探测一次,而 livenessProbe循环探测
- startupProbe用于启动慢(大于30s)的情况下使用
- startupProbe是在容器刚开始启动时进行检测
1.2 Pod探针的实现方式¶
使用探针来检查容器有四种不同的方法。 每个探针都必须准确定义为这四种机制中的一种:
| 实现方式 | 说明 |
|---|---|
| Exec | 在容器内执行一个指定的命令,如果命令返回值为0,则认为容器健康 |
| TCPSocket | 通过TCP连接检查容器指定的端口,如果端口开放,则认为容器健康 |
| HTTPGet(最可靠) | 对指定的URL进行Get请求,如果状态码在200~400(不包括400) 之间,则认为容器健康 |
| gRPC | 1.24版本开始出现,使用gRPC执行一个远程过程调用。 目标应该实现gRPC健康检查。 如果响应的状态是 "SERVING",则认为诊断成功。 gRPC 探针是一个 Alpha 特性,只有在你启用了 "GRPCContainerProbe" 特性门控时才能使用。 |
1.3 Pod探针的探测结果¶
每次探测都将获得以下三种结果之一:
| 种类 | 说明 |
|---|---|
| success | 容器通过了诊断 |
| failure | 容器未通过诊断 |
| unknown | 诊断失败,因此不会采取任何行动 |
二、零宕机发布服务实践¶
参考链接:配置存活、就绪和启动探针
1.模拟没有配置健康检查
(1)创建一个没有探针的 Pod
$ vim nginx01.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: registry.cn-hangzhou.aliyuncs.com/zq-demo/nginx:1.14.2
command:
- sh
- -c
- sleep 25; nginx -g "daemon off;"
imagePullPolicy: Always
restartPolicy: OnFailure
(2)创建Pod
$ k create -f nginx01.yml
(3)查看pod分配IP
$ k get po nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 16s 172.25.244.201 k8s-master01 <none> <none>
(4)测试pod分配IP
$ curl 172.25.244.201
curl: (7) Failed connect to 172.25.244.201:80; Connection refused
上面因为pod没有启动成功,导致pod分配IP测试失败
(5)等待25s后,Pod完全启动成功,再次测试pod分配IP,发现状态码为200,代表成功
$ curl -I 172.25.244.201 2>/dev/null | head -1 | awk '{print $2}'
200
2.配置健康检查-livenessProbe和readinessProbe
(1)定义一个新的yaml文件
$ vim nginx.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: registry.cn-hangzhou.aliyuncs.com/zq-demo/nginx:1.14.2
readinessProbe:
httpGet:
path: /index.html
port: 80
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 5
successThreshold: 1
failureThreshold: 2
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
timeoutSeconds: 2
periodSeconds: 5
successThreshold: 1
failureThreshold: 2
command:
- sh
- -c
- sleep 25; nginx -g "daemon off;"
restartPolicy: OnFailure
上面参数说明:
- initialDelaySeconds:容器启动后要等待多少秒后才启动启动、存活和就绪探针, 默认是 0 秒,最小值是 0。
- periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
- timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。
- successThreshold:探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。
- failureThreshold:探针连续失败了
failureThreshold次之后, Kubernetes 认为总体上检查已失败:容器状态未就绪、不健康、不活跃。 对于启动探针或存活探针而言,如果至少有failureThreshold个探针已失败, Kubernetes 会将容器视为不健康并为这个特定的容器触发重启操作。 kubelet 会考虑该容器的terminationGracePeriodSeconds设置。 对于失败的就绪探针,kubelet 继续运行检查失败的容器,并继续运行更多探针; 因为检查失败,kubelet 将 Pod 的Ready状况设置为false。 - successThreshold: 探针成功了
successThreshold次之后, Kubernetes 认为总体上检查已失败:容器状态就绪、健康、活跃。
(2)创建Pod
$ k create -f nginx.yml
(3)查看pod
$ k get po nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 0/1 Running 0 15s 172.18.195.10 k8s-master03 <none> <none>
此时pod的状态虽然为Running,但是READY为0/1
(4)等待10s左右继续查看Pod,并测试Pod分配IP。此时Pod完全建立
$ k get po nginx
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 3 (33s ago) 2m49s
$ curl -I 172.18.195.10 2>/dev/null | head -1 | awk '{print $2}'
200
3.配置健康检查-startupProbe
有时候,会有一些现有的应用在启动时需要较长的初始化时间。这里可能会有人想到设置固定的探测参数,但是如果只是设置不变的探测参数,当Pod发生故障,等待时间过长导致"无法容忍"。 要这种情况下,若要不影响对死锁作出快速响应的探测,设置存活探测参数是要技巧的。技巧就是使用相同的命令来设置启动探测,针对 HTTP 或 TCP 检测,可以通过将 failureThreshold * periodSeconds 参数设置为足够长的时间来应对糟糕情况下的启动时间。针对这种情况,就出现了startupProbe
下面介绍一下配置健康检查-startupProbe:
(1)定义一个新的yaml文件
$ vim nginx.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: registry.cn-hangzhou.aliyuncs.com/zq-demo/nginx:1.14.2
startupProbe:
tcpSocket:
port: 80
initialDelaySeconds: 2
timeoutSeconds: 2
periodSeconds: 5
successThreshold: 1
failureThreshold: 20
readinessProbe:
httpGet:
path: /index.html
port: 80
scheme: HTTP
initialDelaySeconds: 2
timeoutSeconds: 2
periodSeconds: 5
successThreshold: 1
failureThreshold: 2
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 2
timeoutSeconds: 2
periodSeconds: 5
successThreshold: 1
failureThreshold: 2
command:
- sh
- -c
- sleep 30; nginx -g "daemon off;"
上面参数说明:
- initialDelaySeconds:容器启动后要等待多少秒后才启动启动、存活和就绪探针, 默认是 0 秒,最小值是 0。
- periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
- timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。
- successThreshold:探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。
- failureThreshold:探针连续失败了
failureThreshold次之后, Kubernetes 认为总体上检查已失败:容器状态未就绪、不健康、不活跃。 对于启动探针或存活探针而言,如果至少有failureThreshold个探针已失败, Kubernetes 会将容器视为不健康并为这个特定的容器触发重启操作。 kubelet 会考虑该容器的terminationGracePeriodSeconds设置。 对于失败的就绪探针,kubelet 继续运行检查失败的容器,并继续运行更多探针; 因为检查失败,kubelet 将 Pod 的Ready状况设置为false。 - successThreshold: 探针成功了
successThreshold次之后, Kubernetes 认为总体上检查已失败:容器状态就绪、健康、活跃。
(2)创建Pod
$ k create -f nginx.yml
(3)查看pod状态,初始时READY为0/1,状态为Running
$ k get po nginx
NAME READY STATUS RESTARTS AGE
nginx 0/1 Running 0 5s
(4)等待30s左右再次查看pod状态,初始时READY为1/1,状态为Running
$ k get po nginx
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 40s
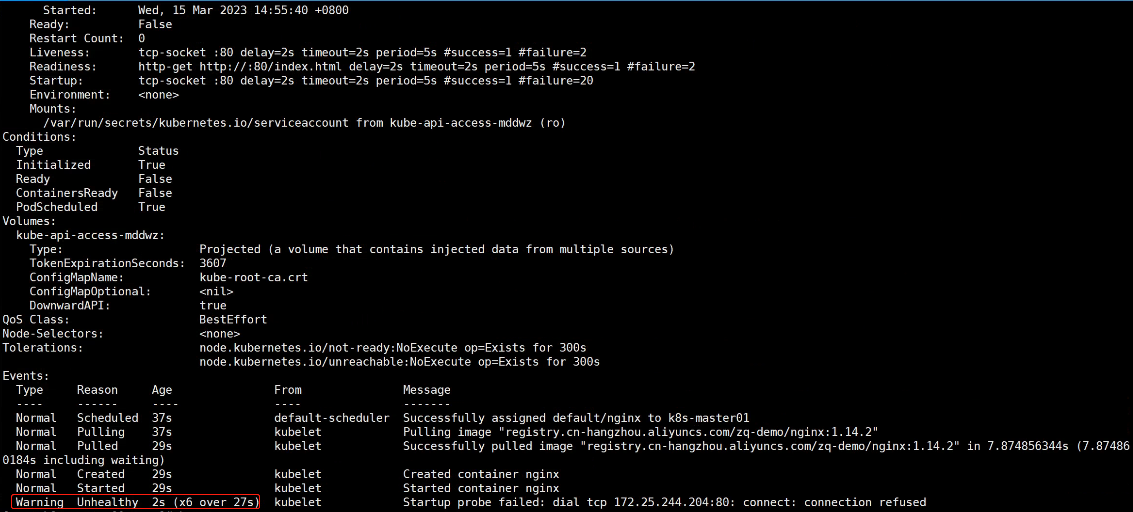
当然我们也可以通过kubectl describe查看重启次数,这里因为我们设置的睡眠时间为30s,探测时间为5s,所以大概在第6次Pod会完全起来。
$ k describe po nginx