

当此类告警被触发,在一个“group_wait”时间范围内,会被汇集成一个通知发出来,比如只发一条微信消息或者一封邮件。
案例一:最简单的分组,通过alertname来分组
关键配置项:
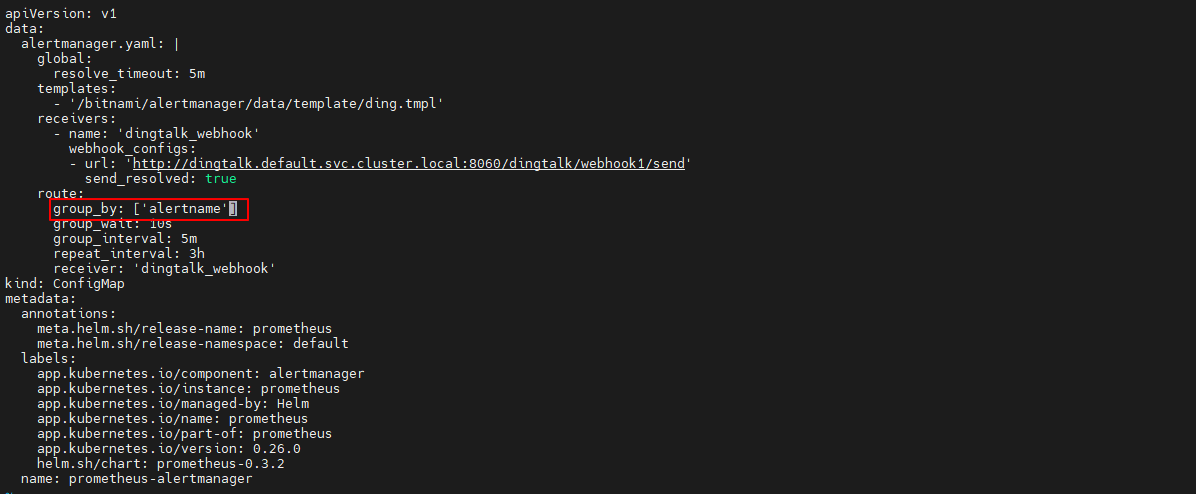
1)编辑alertmanager_config.yml配置文件,一般在route:文件下面
route:
group_by: ['alertname']
这个alertname 指的是告警规则里alert参数定义的值。
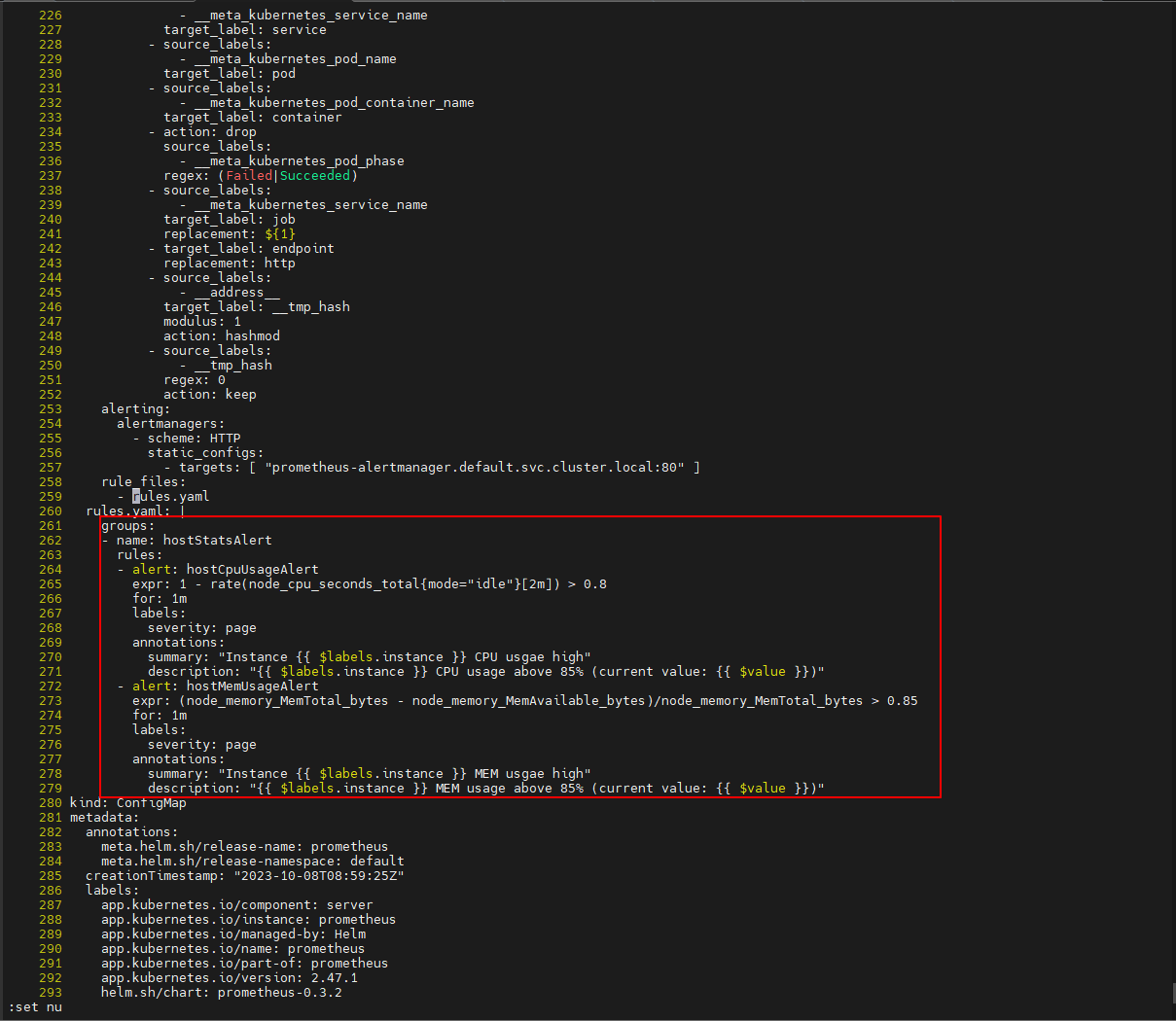
2)prometheus 的 告警规则配置文件
找到rules.yaml,编辑对应的部分
$ vi prometheus_config.yaml
groups:
- name: hardware
rules:
- alert: hardware
expr: node_load1 > 4
for: 1m
labels:
severity: Critical
annotations:
summary: "{{ $labels.instance }} 负载为 {{ $value }} 比较高 "
description: "主机1分钟负载超过4"
value: "{{ $value }}"
- alert: hardware
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 1m
labels:
severity: Critical
annotations:
summary: "{{$labels.instance}} CPU使用率为{{ $value }} 太高"
description: "{{$labels.instance }} CPU使用大于80%"
value: "{{ $value }}%"
- alert: hardware
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 85
for: 1m
labels:
severity: Critical
annotations:
summary: "{{$labels.instance}} 内存使用率 {{ $value }}% 过高!"
description: "{{$labels.instance }} 内存使用大于85%"
value: "{{ $value }}%"
案例二:通过alertname + 额外标签区分
关键配置项:
1)编辑alertmanager_config.yml配置文件,一般在route:文件下面
route:
group_by: ['alertname']
说明:这个alertname 指的是告警规则里alert参数定义的值。
2)prometheus 的 告警规则配置文件
找到rules.yaml,编辑对应的部分
$ vi prometheus_config.yaml
groups:
- name: hardware
rules:
- alert: hardware
expr: node_load1 > 4
for: 1m
labels:
severity: Critical
team: cpu
annotations:
summary: "{{ $labels.instance }} 负载为 {{ $value }} 比较高 "
description: "主机1分钟负载超过4"
value: "{{ $value }}"
- alert: hardware
expr: 100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 1m
labels:
severity: Critical
team: cpu
annotations:
summary: "{{$labels.instance}} CPU使用率为{{ $value }} 太高"
description: "{{$labels.instance }} CPU使用大于80%"
value: "{{ $value }}%"
- alert: hardware
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 85
for: 1m
labels:
severity: Critical
team: mem
annotations:
summary: "{{$labels.instance}} 内存使用率 {{ $value }}% 过高!"
description: "{{$labels.instance }} 内存使用大于85%"
value: "{{ $value }}%"