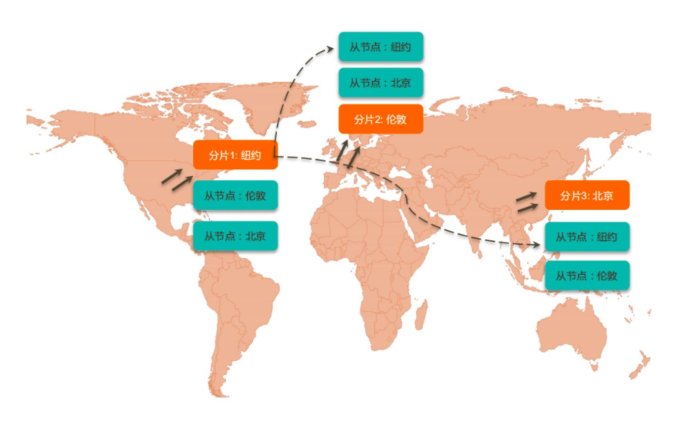
一、为什么使用分片集群¶
- 数据容量日益增大,访问性能日渐降低,怎么破?
- 新品上线异常火爆,如何支撑更多的并发用户?
- 单库已有 10TB 数据,恢复需要 1-2天,如何加速?
- 地理分布数据
二、如何解决以上问题¶
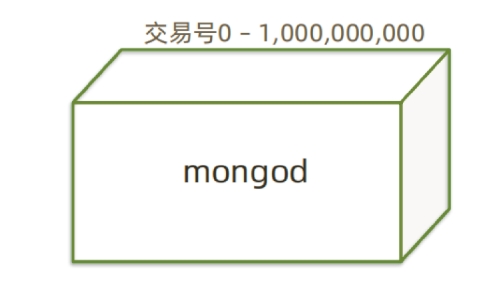
2.1 原始结构¶
- 银行交易单表内 10亿笔资料
- 超负荷运转
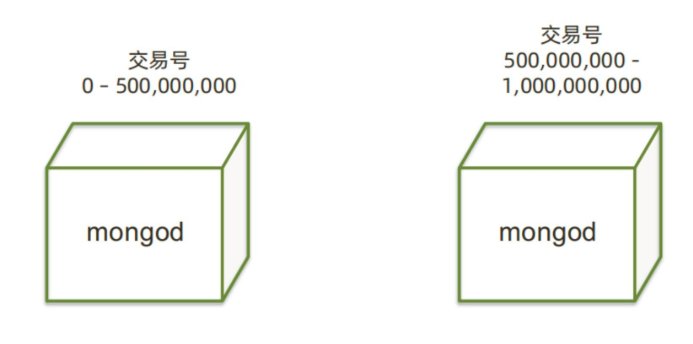
2.2 把数据分成两半¶
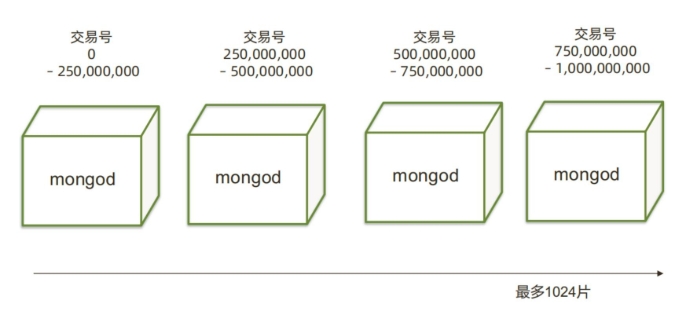
2.3 把数据分成 4部分¶
三、分片架构介绍¶
下图描述了分片集群内组件的交互:
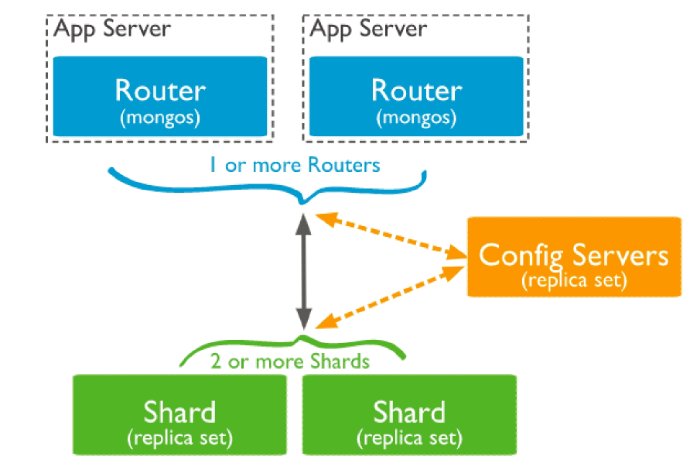
分片集群由以下组件组成 :shard/mongos/configServer #Mongos 路由节点
提供集群单一入口
转发应用端请求
选择合适数据节点进行读写
合并多个数据节点的返回
无状态
建议至少 2个
Config Servers配置节点
提供集群元数据存储
分片数据分布的映射
Shards 数据节点
以复制集为单位
横向扩展
最大 1024分片
分片之间数据不重复
所有分片在一起才可完整工作
四、MongoDB 分片集群特点¶
- 应用全透明,无特殊处理
- 数据自动均衡
- 动态扩容,无须下线
- 提供三种分片方式
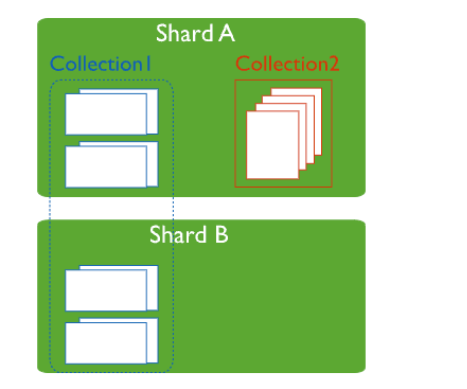
4.1 分片和非分片集合¶
Unsharded 集合 - 存储在主分片上
sharded 集合
- 分布在集群中的分片上
五、分片集群数据分布方式¶
- 基于范围
- 基于 Hash
- 基于 zone / tag
5.1 分片集群数据分布方式 – 基于范围¶
缺点:容易有热点。
比如 2个分片,一个分片存 1-500w,一个分片存 500w-1000w
但是热点数据是 300w-400w。虽然数据是均衡的,但还是有热点数据,总有很忙 /很闲的分片。 也可以建议做多条件的范围分区。

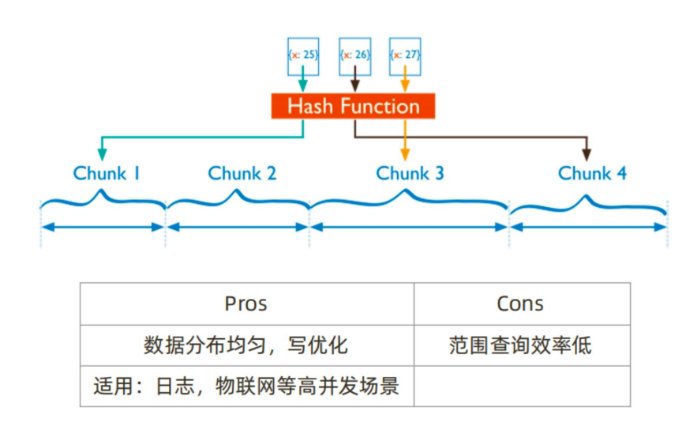
5.2 分片集群数据分布方式 – 基于哈希¶
优点:数据分布非常均匀,适合等值查询。
缺点:范围查询的效率低(因为分布的过于零散),将来 mongos的合并 merge会比较多。
5.3 分片集群数据分布方式 – 自定义 Zone¶
适合:跨地域的多写场景。读写请求落到就近的节点上。