

一、高级数据类型¶
1.1 bitmap(位存储)¶
简介
-
bitmap 是位图数据结构,只有0 和 1 两个状态
-
Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value),但是它可以对字符串的位进行操 作。


常用命令
使用bitmap 来记录 周一到周日的打卡! 周日:1 周一:1 周二:1 周三:0 周四:1 周五:0 周六:1
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 1
(integer) 0
127.0.0.1:6379> setbit sign 3 0
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 0
(integer) 0
127.0.0.1:6379> setbit sign 6 1
(integer) 0
查看某一天是否有打卡
127.0.0.1:6379> getbit sign 4
(integer) 1
127.0.0.1:6379> getbit sign 5
(integer) 0
统计操作,统计打卡的天数!
127.0.0.1:6379> bitcount sign # 统计这周的打卡记录,就可以看到是否有全勤!
(integer) 5
应用场景
-
网络流量分析
-
签到
-
布隆过滤器
-
活跃用户统计
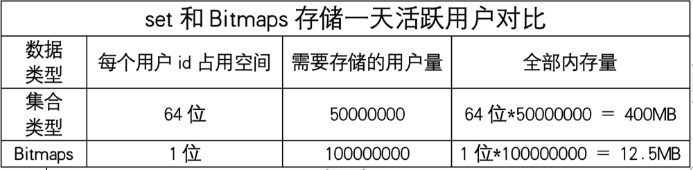
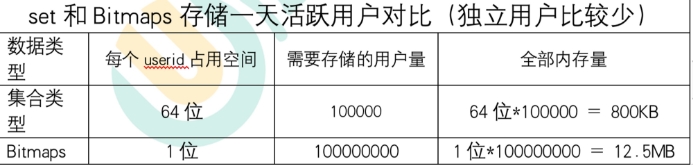
bitmaps与set对比
-
假设网站有1亿用户, 每天独立访问的用户有5千万, 如果每天用集合类型和Bitmaps分别存储活跃用户 可以得到表。使用Bitmaps能节省很多的内存空间。
-
假如该网站每天的独立访问用户很少,例如只有10万(大量的僵尸用户),这时候使用Bitmaps就不太合适 了,因为基本上大部分位都是0。

1.2 HyperLogLog(基数统计)¶
简介
HyperLogLog
-
Redis 2.8.9 版本更新了 Hyperloglog 数据结构
-
HyperLogLog 并不是一种新的数据结构(实际类型为字符串类型),而是一种基数算法
-
可利用极小的内存空间完成独立总数的统计
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数(不重复 元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
常用命令
添加
pfadd key element [element …] #添加指定元素到 HyperLogLog 中
计算独立用户数,也就是基数数量
pfcount key [key …] #计算HLL的近似基数,可以计算多个HLL,比如用HLL存储每天的UV,计 算一周的UV可以使用7天的UV合并计算即可
合并
pfmerge destkey sourcekey [sourcekey ...] #将一个或多个HLL合并后的结果存储在另一个HLL 中,比如每月活跃用户可以使用每天的活跃用户来合并计算可得
示例
127.0.0.1:6379> pfadd pfkey1 a b c d e f g h i a a # 创建第一组元素
(integer) 1
127.0.0.1:6379> pfcount pfkey1 # 统计元素的基数数量
(integer) 9
127.0.0.1:6379> pfadd pfkey2 c j k l m e g a # 创建第二组元素
(integer) 1
127.0.0.1:6379> pfcount pfkey2
(integer) 8
127.0.0.1:6379> pfmerge pfkey3 pfkey1 pfkey2 # 合并两组:pfkey1 pfkey2 -> pfkey3 并集
OK
127.0.0.1:6379> pfcount pfkey3
(integer) 13
应用场景
- pv与uv的统计
集合类型和HyperLogLog 占用空间对比

1.3 geospatial (地理位置)¶
1、简介
-
Redis 的 Geo 在 Redis 3.2 版本就推出了!
-
这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人。
-
geo底层的实现原理实际上就是Zset, 可以通过Zset命令来操作geo
2、常用命令
增加地理位置信息
geoadd key longitude latitude member [longitude latitude member ...]
_>>longitude、latitude、member分别是该地理位置的经度、纬度、成员
127.0.0.1:6379> geoadd china:city 116.28 39.55 beijing 112.55 37.86 taiyuan 123.43 41.80 shenyang
(integer) 3
127.0.0.1:6379> geoadd china:city 119.01 39.38 tangshan 120.16 30.24 hangzhou 108.96 34.26 xianjin
(integer) 3
规则:
-
有效的经度从-180度到180度。
-
有效的纬度从-85.05112878度到85.05112878度。
当坐标位置超出上述指定范围时,该命令将会返回一个错误。
127.0.0.1:6379> geoadd china:city 39.90 116.40 shanghai
(error) ERR invalid longitude,latitude pair 39.900000,116.400000
获取地理位置信息
geopos key member [member ...]
127.0.0.1:6379> geopos china:city beijing taiyuan #获取北京、太原的经纬度信息
1) 1) "116.28000229597091675"
2) "39.5500007245470826"
2) 1) "112\.54999905824661255"
2) "37\.86000073876942196"
获取两个地理位置的距离
geodist key member1 member2 [unit] #如果不存在, 返回空 其中unit代表返回结果的单位,包含以下四种:
-
m(meters)代表米
-
km(kilometers)代表公里
-
mi(miles)代表英里,240
-
ft(feet)代表英尺
127.0.0.1:6379> geodist china:city taiyuan shenyang m
"1026439.1070"
127.0.0.1:6379> geodist china:city taiyuan shenyang km
"1026.4391"
获取指定位置范围内的地理信息位置集合, 附近的人 ==> 获得所有附近的人的地址, 定位, 通过半径 来查询
georadius key longitude latitude radius m|km|ft|mi georadiusbymember key member radius m|km|ft|mi
- radiusm|km|ft|mi是必需参数,指定了半径(带单位)
其他可选参数:
-
withcoord:返回结果中包含经纬度
-
withdist:返回结果中包含离中心节点位置的距离
-
withhash:返回结果中包含geohash
-
COUNT count:指定返回结果的数量
-
asc|desc:返回结果按照离中心节点的距离做升序或者降序。
计算几个城市中,距离北京300公里以内的城市
127.0.0.1:6379> georadiusbymember china:city beijing 300 km
1) "beijing"
1) "tangshan"
以 110,30 这个坐标为中心, 寻找半径为1000km的城市
127.0.0.1:6379> georadius china:city 110 30 1000 km
1) "xianjin"
1) "hangzhou"
1) "taiyuan"
以 110,30 这个坐标为中心, 寻找半径为500km的城市,并返回离中心节点的距离
127.0.0.1:6379> georadius china:city 110 30 500 km withdist
1) 1) "xianjin"
2) "483.8340"
以 110,30 这个坐标为中心, 寻找半径为500km的城市,并返回离中心节点的距离、以及中心节点的经纬 度
127.0.0.1:6379> georadius china:city 110 30 500 km withcoord withdist count 2
1) 1) "xianjin"
2) "483.8340"
3) 1) "108.96000176668167114"
2) "34.25999964418929977"
获取geohash
geohash key member [member ...]
127.0.0.1:6379> geohash china:city beijing
1) "wx48ypbe2q0"
使用zset命令操作geo
127.0.0.1:6379> type china:city
zset
查看全部元素
127.0.0.1:6379> zrange china:city 0 -1 withscores
1) "xian"
2) "4040115445396757"
3) "hangzhou"
4) "4054133997236782"
5) "manjing"
6) "4066006694128997"
7) "taiyuan"
8) "4068216047500484"
9) "shenyang"
1) "4072519231994779"
2) "shengzhen"
3) "4154606886655324"
删除指定的元素
127.0.0.1:6379> zrem china:city manjing
(integer) 1
127.0.0.1:6379> zrange china:city 0 -1
1) "xian"
2) "hangzhou"
3) "taiyuan"
4) "shenyang"
5) "shengzhen"
3、应用场景
附近的人
二、key管理¶
2.1 单个键管理¶
键重命名
rename key newkey renamenx key newkey
随机返回一个键
randomkey
键过期
expire key seconds #key在seconds秒后过期。
expireat key timestamp #key在秒级时间戳timestamp后过期。
ttl key #返回还剩余多少秒过期
pttl key #返回还剩余多少毫秒过期
pexpire key milliseconds #key在milliseconds毫秒后过期。 pexpireat key milliseconds-timestamp #key在毫秒级时间戳timestamp后过期 persist key # 移除给定 key 的过期时间,使得 key 永不过期
注意:
-
如果expire key的键不存在,返回结果为0
-
如果过期时间为负值,键会立即被删除,犹如使用del命令一样
-
persist命令可以将键的过期时间清除
-
对于字符串类型键,执行set命令会去掉过期时间
-
Redis不支持二级数据结构(例如哈希、列表)内部元素的过期功能,例如不能对列表类型的一个元素做过 期时间设置
-
setex命令作为set+expire的组合,不但是原子执行,同时减少了一次网络通讯的时间
示例
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> expire hello 10
(integer) 1
还剩7秒
127.0.0.1:6379> ttl hello
(integer) 7
...
还剩0秒
127.0.0.1:6379> ttl hello
(integer) 0
#返回结果为-2,说明键hello已经被删除
127.0.0.1:6379> ttl hello
(integer) -2
2.2 遍历¶
全量遍历键
keys pattern
keys pattern
- pattern使用的是glob风格的通配符:
* 代表匹配任意字符。 代表匹配一个字符。
[]代表匹配部分字符,例如[1,3]代表匹配1,3,[1-10]代表匹配1到10 的任意数字
\x用来做转义,例如要匹配星号、问号需要进行转义
渐进式遍历
scan cursor [match pattern] [count number]
- cursor,必需参数,是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游
标值为0,表示遍历结束。
-
match pattern,可选参数,做模式的匹配
-
count number,可选参数,表示每次要遍历的键个数,默认值是10
其他遍历命令: hscan、sscan、zscan
遍历某个前缀的key的数量
使用方法
python scan_key.py aaa* 100
遍历redis中以aaa为前缀key的个数,每次遍历100个。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# 作用:统计某个前缀key的个数,并将其写入到文件
__author__ = "linda"
import sys
import redis
import os
pool = redis.ConnectionPool(host='192.168.9.144', port=6379, db=0, password='linda123')
r = redis.StrictRedis(connection_pool=pool)
# 扫描匹配值,通过sys.argv传参
match = sys.argv[1]
match_list = match.split("|")
print match_list
# 每次匹配数量
count = sys.argv[2]
path = os.getcwd()
# 扫描到的key输出的文件
txt = path + "/keys.txt"
f = open(txt, "w")
for i in match_list:
print "key前缀为:%s" % i
total = 0
for key in r.scan_iter(match=i, count=count):
f.write(key + "\n")
total = total + 1
if total % 100000 == 0:
print("total=%s" % total)
print "匹配: %s 的数量为:%d " % (i, total)
f.close
2.3 数据库管理¶
切换数据库
select dbIndex
说明: 生产环境建议只使用0号数据库,如果想要使用多个数据库功能,可以在一台机器上部署多个Redis实例,彼此 用端口来做区分。这样既保证了业务之间不会受到影响,又合理地使用了CPU资源。
- 清空数据库
flushdb/flushall
说明: 生产环境使用rename-command配置规避掉flushdb/flushall命令,防止误操作。