

一、Redis Cluster核心原理¶
1.1 gossip通信流程¶
1.1.1 gossip简介¶
1.分布式存储维护节点meta info:那些节点负责那些数据,故障状态
2.常见元数据维护方式: 集中式 or P2P
3.redis敢用p2p的gossip(流言)协议
- 节点彼此一直交换信息,一段时间后所有节点知道集群完整信息
- redis过程说明
1)集群每个节点单独开辟一个TCP通道,用于节点间通信,redis端口+10000
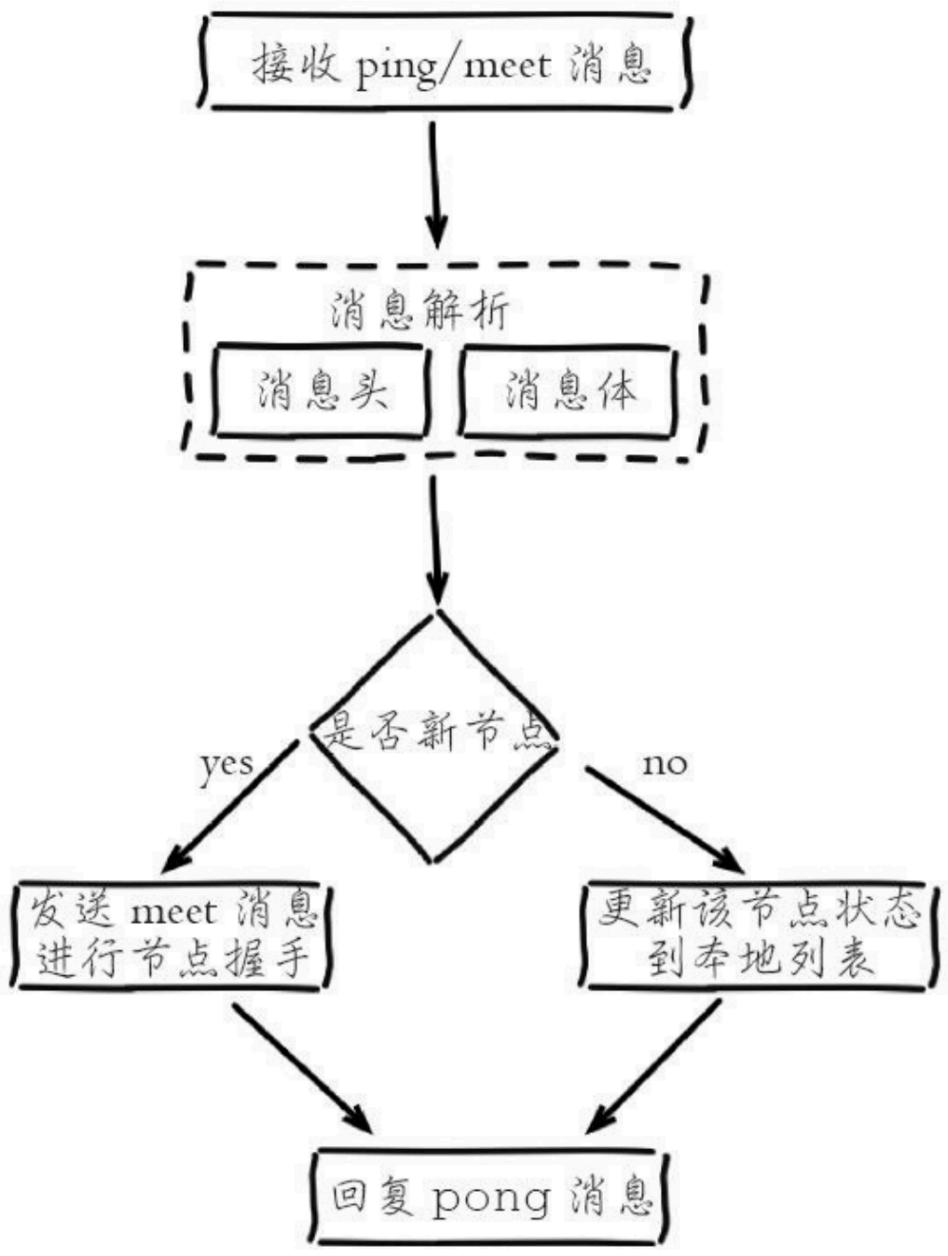
2)节点在固定周期内根据特定规则发送ping消息
3)收到Ping的节点恢复pong消息
4)随着节点加入 故障 slot变化,不断通过ping/pong消息通信,一段时间后所有node知道cluster的最新状态,集群信息同步
1.1.2 gossip消息类型¶
redis常用的gossip消息:ping,pong,meet,fail
1.meet:新节点加入
2.ping:集群交换最频繁信息,监测在线和集群信息状态,封装自己和其他节点部分状态数据
3.pong:接受ping meet 作为消息回应,同时封装了自身的数据
4.fail:判定集群节点下线的fail消息,其他node收到后更新下线状态
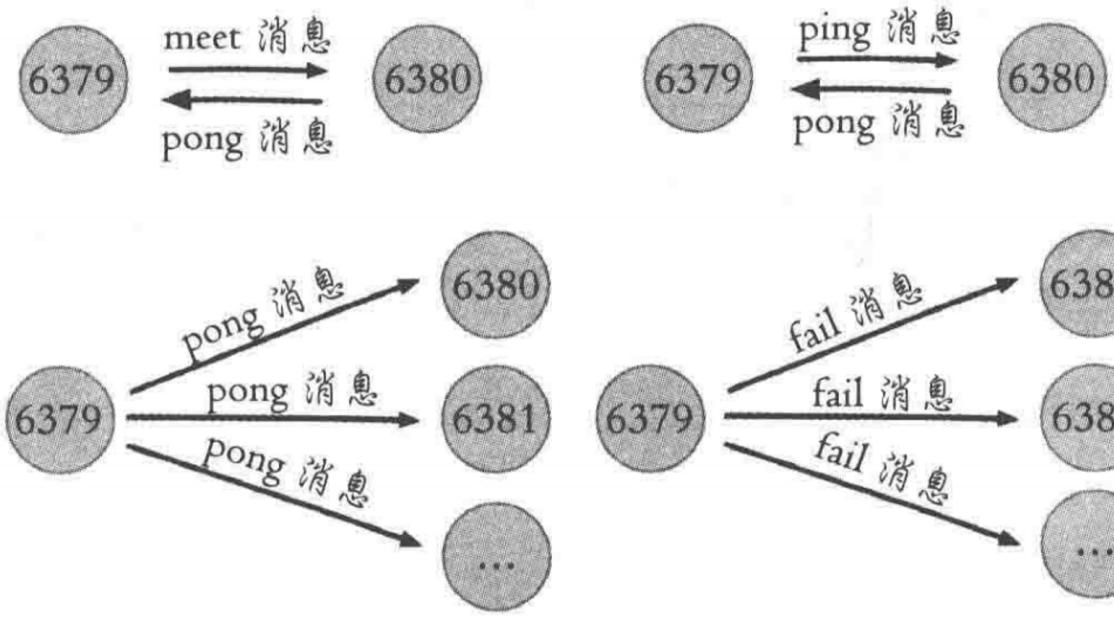
ping和meet的消息接受流程
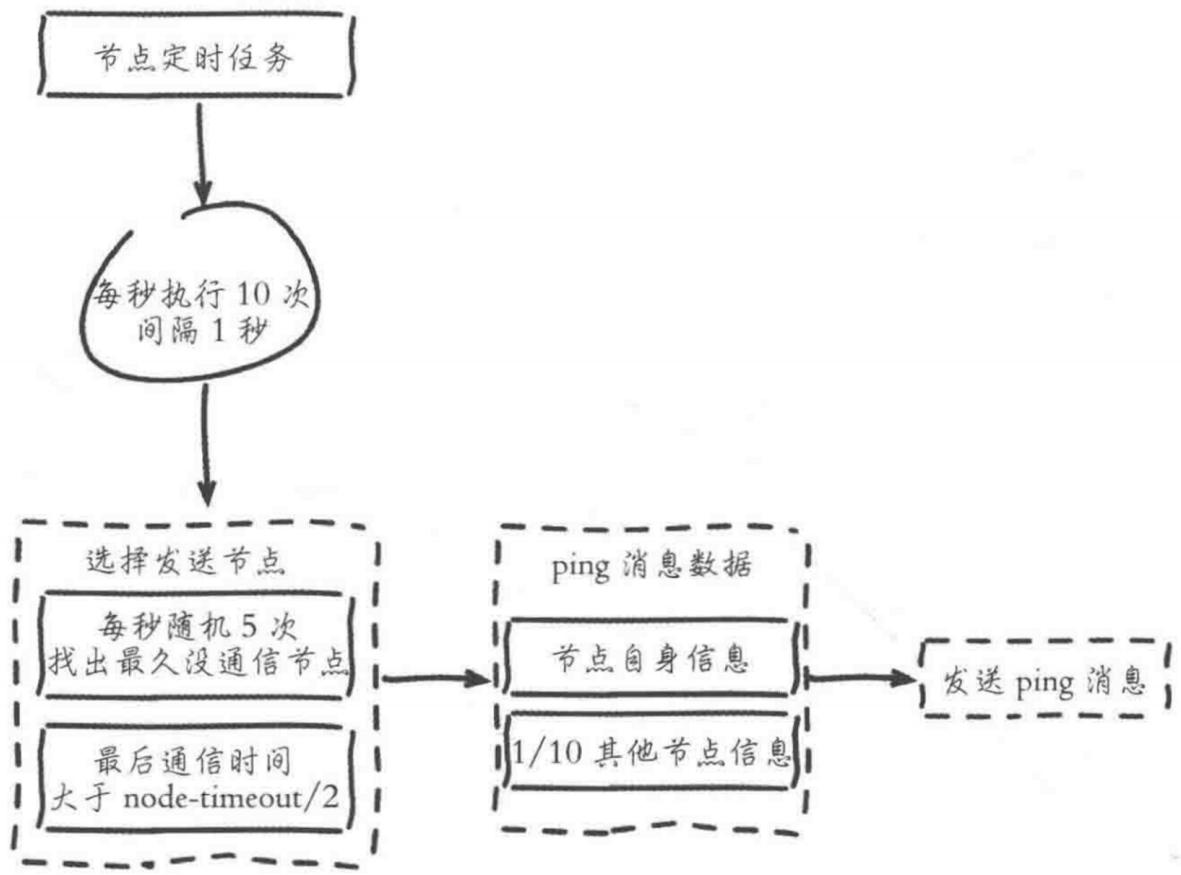
节点通信选择-兼容实时和成本
1.通信是个定时任务
2.每秒10次,1秒1次
3.发送节点
- 5个最久没通信节点
- 通信时间大于 node-timeout/2
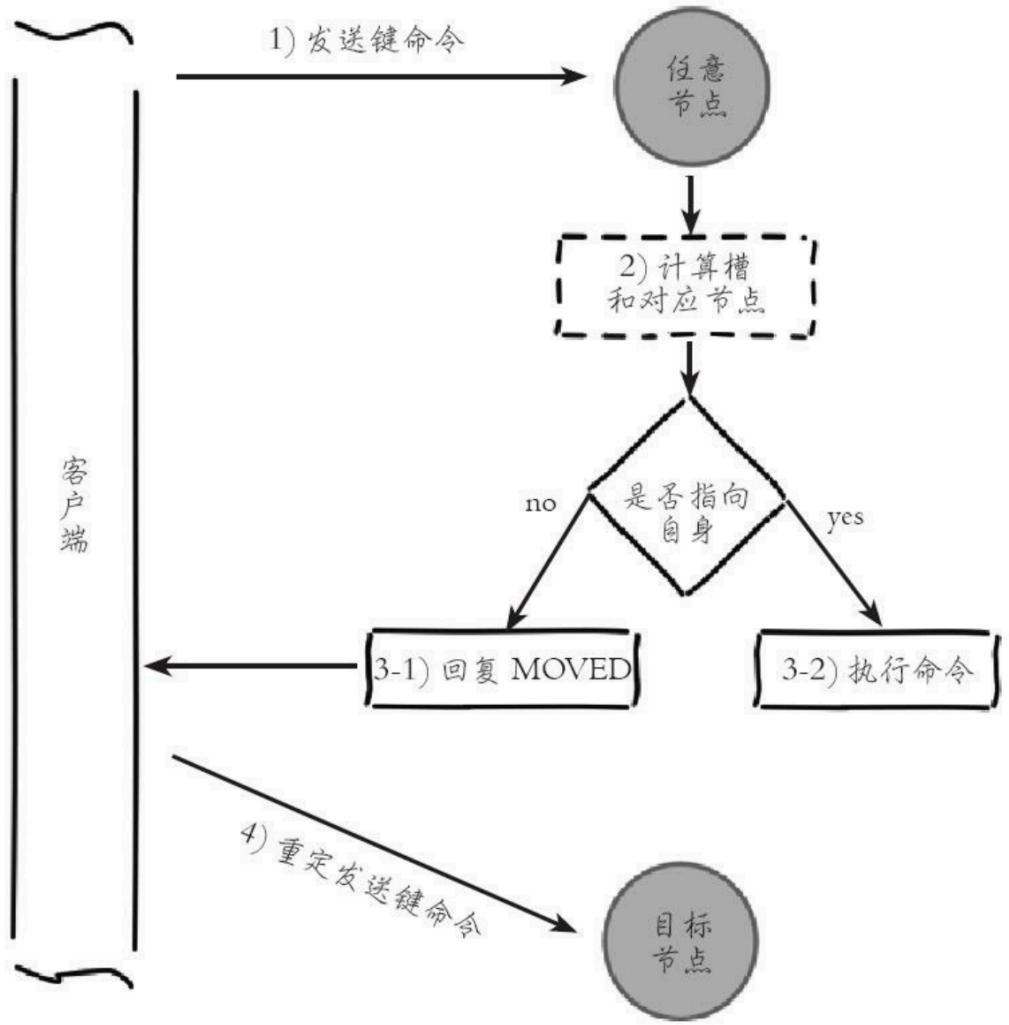
1.2 请求路由¶
#概念
在集群模式下,Redis接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则
处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点。
#示例
1.cluster,redis得到命令先计算slot--》找到node-->自身 处理命令--》不是自己回复MOVED重定向到正确节
点
GET x
-MOVED 3999 127.0.0.1:6381
#查看key的slot
cluster keyslot keu:test:1
#请求重定向注意事项
- 网络延迟和性能会影响请求重定向的效率,需要保证集群节点之间的网络连接稳定可靠。
- 请求重定向会增加集群节点的负载,可能会导致客户端的性能下降,因此需要在开发中进行评估和优化。
- 集群节点的扩容和缩容也会影响请求重定向的效率和正确性,需要注意集群拓扑的变化对请求重定向的影响。
ASK重定向
场景:Cluster迁移时使用
1.一个slot迁移会很难节点的该槽位被设置为migrating状态,B节点被设置为importing的槽位(CLUSTER
SETSLOT命令)
2.获得节点的key列表-->逐个key迁移(A节点用dump命令序列化-->B节点restore反序列化)
3.对应的key从A节点删除
在迁移A时-->客户端节后请求:
1.key还未迁移A返回结果
2.键值迁移-ASK targetNodeAddr重定向到B
3.B当成自己key处理,如果有则处理命令
ASK与MOVED的本质区别:
- ASK重定向说明集群正在进行slot数据迁移,客户端无法知道什么时候迁移完成,因此只能是临时性的重定向,客户
端不会更新slots缓存
- MOVED重定向说明键对应的槽已经明确指定到新的节点,因此需要更新slots缓存

ASK重定向流程
1.3 故障发现¶
故障发现(通过ping/pong节点)主要环节:
-
主观下线(pfail)
-
客观下线(fail)
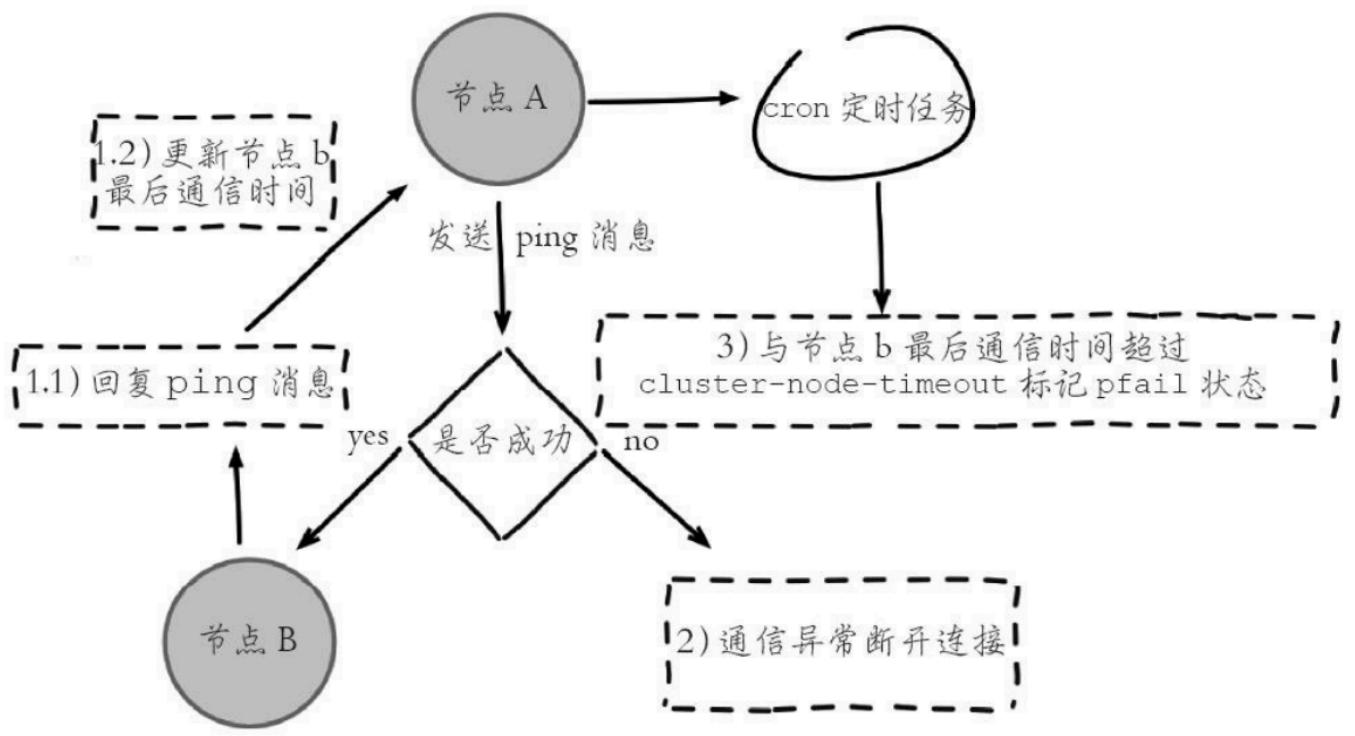
1.3.1 主观下线¶
主观:某个node认为一个node不可用
客观:多数节点达成节点一致不可用,进行故障转移
主观下线识别流程
1.3.2 客观下线¶
主节点才有权利下线,半数以上对网络分区场景
1、节点信息gossip给其他节点,接受节点发现pfail下线消息
2、更新自己的clusternode消息结构,广播
3、其他节点进行更新判定 达到多数则fail下线
4、集群广播fail,通知所有节点客观下线 node id
5、触发从节点故障转移流程
客观下线逻辑流程
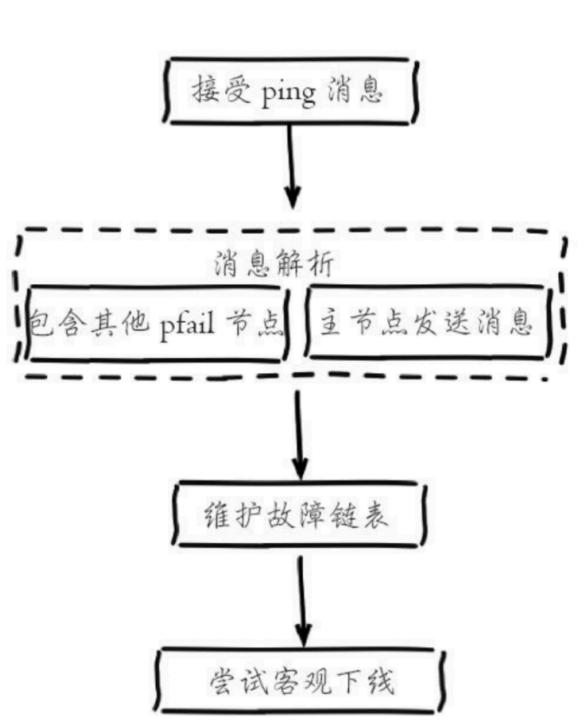
尝试客观下线流程

1.4 故障转移¶
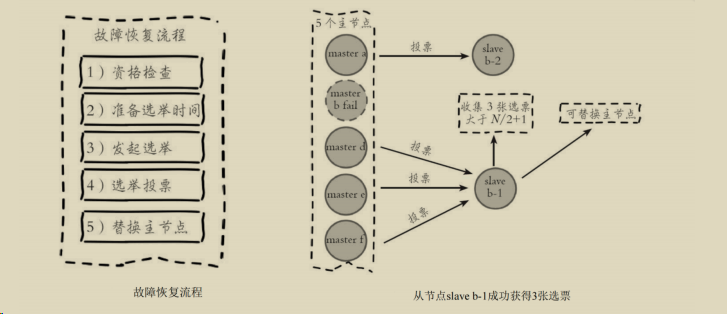
slave发现复制的master进入fail时,则会触发故障恢复流程:
1.资格检查
判断与master断线时间,是否是新节点具备资格选举,看我与主节点连接时间是否很新
> cluster-node-time*cluster-slave-validity-factor 则slave不具备故障转移资格
2.准备选举时间
slave根据自身复制偏移量设置延迟选举时间,复制偏移量最大的slave将提前触发故障选举流程
3.发起选举
- 更新配置纪元(集群最大版本), 应用场景:新节点接入、slot冲突、从节点投票选举冲突检测
- 广播选举消息
127.0.0.1:6379> cluster info
cluster_current_epoch:15 # 整个集群最大配置纪元
cluster_my_epoch:13 # 当前主节点配置纪元
4.投票选举
- 主节点进行投票
- 大于半数以上,选举成功
5.替换主节点
- slave取消复制变为主节点
- 执行clusteraddslot把slot委派给自己
- 广播pong消息
6.故障节点启动
- 发现自己slot没有,则成为新主节点的从节点
故障转移的时间:
failover-time(毫秒) ≤ cluster-node-timeout + cluster-node-timeout/2 + 1000(毫秒)
二、Redis Cluster运维管理¶
2.1 操作命令管理¶
2.1.1 cluster info¶
192.168.225.130:8200> cluster info
cluster_state:ok //fail, 如果节点能够接收查询,,为ok;如果一个slot未绑定,处于错
误状态,则为fail
cluster_slots_assigned:16384 //要使节点正常工作,这个数字应该是16384,这意味着每个哈希槽应该映
射到一个节点。
cluster_slots_ok:16384 // 映射到未处于fail 或PFAIL状态的节点的哈希槽数。
cluster_slots_pfail:0 // 处于PFAIL状态的节点的哈希槽数。注意,只要故障检测算法没有将
PFAIL状态提升为FAIL,这些哈希槽仍然可以正常工作。PFAIL只意味着我们目前不能与节点通信,但可能只是一个暂
时的错误。
cluster_slots_fail:0 // 处于fail节点的哈希槽数,假如该数值不为0,则该节点不能提供查
询。除非配置中将cluster-require-full-coverage 设置为 no
cluster_known_nodes:6 // 集群中节点的总数
cluster_size:3 // 集群中master节点的数量
cluster_current_epoch:6 // 本地当前epoch变量。用于在故障转移期间创建惟一的递增版本号。
cluster_my_epoch:1 // 我们正在讨论的节点的配置纪元。这是分配给该节点的当前配置版本。
cluster_stats_messages_ping_sent:1298
cluster_stats_messages_pong_sent:832
cluster_stats_messages_sent:2130 // 集群node-to-node二进制总线发送的消息数量
cluster_stats_messages_ping_received:832
cluster_stats_messages_pong_received:849
cluster_stats_messages_received:1681 // 集群node-to-node二进制总线接收的消息数量
2.1.2 cluster nodes¶
查看所有节点的状态信息
192.168.9.78:6510> cluster nodes
69bc68c2ef584fcd3aadc645cdad2e313128bd44 127.0.0.1:6510@16510 master - 0 1686137124000
1 connected 1364-5460
e5663e0168079eb26064e1d1bfc720506066962e 127.0.0.1:6522@16522 slave
69bc68c2ef584fcd3aadc645cdad2e313128bd44 0 1686137123000 1 connected
2.1.3 cluster slots¶
192.168.225.130:8200> cluster slots
192.168.9.78:6510> cluster slots
1) 1) (integer) 0 //开始slot位置
2) (integer) 1363 //结束slot位置
3) 1) "127.0.0.1" //master IP
2) (integer) 6530 //master port
3) "a4cb8f370148cbc3f67ea5b69d839f6008904804" //master node_id
4) 1) "127.0.0.1" //slave IP
2) (integer) 6531 //slave port
3) "caf7434be9150a3599d1d2e365ac0eab319b835c" //slave node_id
2.1.4 cluster addslots¶
(该命令执行的时候需要在需要addslot的master上执行,才会生效,其他节点执行出现ok,但是实际是不成功的.只有当所有指定的slot都已与某个节点关联时,该命令才有效)
(该命令执行的时候需要在需要addslot的master上执行,才会生效,其他节点执行出现ok,但是实际是不成功的.只
有当所有指定的slot都已与某个节点关联时,该命令才有效)
> cluster addslots 10000
addslots多个:
for ((i=10923;i<=16383;i++)); do /data/redis/bin/redis-cli -h 192.168.9.78 -
p 6383 CLUSTER ADDSLOTS ${i} ; done
2.1.5 cluster delslots¶
该命令执行的时候需要在10000这个slot所在的master上执行,才会生效,其他节点执行出现ok,但是实际是不成功的.只有当所有指定的插槽都已与某个节点关联时,该命令才有效
> cluster delslots 10000
2.1.6 cluster failover¶
手动failover支持三种模式的failover:
- 缺省(manual)
- force
- takeover
#manual
说明:该命令只能在群集slave节点执行,让slave节点进行一次人工故障切换。
流程如下:
(1) 当前slave节点告知其master节点停止处理来自客户端的请求
(2) master 节点将当前replication offset 回复给该slave节点
(3) 该slave节点在未应用至replication offset之前不做任何操作,以保证master传来的数据均被处理。
(4) 该slave 节点进行故障转移,从群集中大多数的master节点获取epoch,然后广播自己的最新配置
(5) 原master节点收到配置更新:解除客户端的访问阻塞,回复重定向信息,以便客户端可以和新master通信。
当该slave节点(将切换为新master节点)处理完来自master的所有复制,客户端的访问将会自动由原master节点切
换至新master节点
#FORCE
说明:master节点down的情况下的人工故障转移
FORCE 选项:slave节点不和master协商(master也许已不可达),从上如4点开始进行故障切换。当master已不可
用,而我们想要做人工故障转移时,该选项很有用。
#TAKEOVER
说明:忽略群集一致验证的的人工故障切换,无群集共识的手动故障转移
举例: 群集中主节点和从节点在不同的数据中心,当所有主节点down掉或被网络分区隔离,需要用该参数将slave节点
批量切换为master节点。
流程如下:
(1)独自生成新的configEpoch,若本地配置epoch非最大的,则取当前有效epoch值中的最大值并自增作为新的配置
epoch
(2)将原master节点管理的所有哈希槽分配给自己,同时尽快分发最新的配置给所有当前可达节点,以及后续恢复的故
障节点,期望最终配置分发至所有节点
2.1.7 cluster meet¶
cluster meet <ip> <port>
2.1.8 cluster forget¶
192.168.225.130:8200> cluster forget 31baabca10f43d06737a17a121b09148fa82d361
OK
集群一次性forget某个node
ip_list=("172.21.100.100:6381" "172.21.100.101:6382" "172.21.100.102:6382")
for ip in "${ip_list[@]}"; do redis-cli -h "${ip%:*}" -p "${ip#*:}" -a '密码' CLUSTER
FORGET ca1d5e20e7183bfda7d872bab607c352d65f53ca; done
2.1.9 其他命令¶
#cluster slaves node-id //获取指定主节点的所有从节点信息,node_id为master的node_id
#cluster replicas node-id //(node_id为master的node_id)
说明:让一个节点成为从节点。其中命令执行必须在对应的从节点上执行,nodeId是要复制主节点的节点ID
#cluster keyslot <keyname>
说明:返回的是一个整数,aaa这个key所在的slot,一个slot里面肯定会有很多个key
127.0.0.1:6530> cluster keyslot aaa
(integer) 10439
#cluster count-failure-reports node-id
说明:该命令返回指定节点的失败报告数量。
192.168.225.130:8200> cluster count-failure-reports
d4f57781dd9979f2a1b9d45f7d8ae66d818989c3
(integer) 0
#cluster countkeysinslot ,slot里面key的数量
127.0.0.1:6511> cluster countkeysinslot 10439
(integer) 1
#cluster getkeysinslot
127.0.0.1:6511> cluster getkeysinslot 10439 10 #说明:10439为slot,10,表示:返回该槽里面的
10个key。返回结果为数组
1) "aaa"
说明:让一个节点成为从节点。其中命令执行必须在对应的从节点上执行,nodeId是要复制主节点的节点ID
cluster keyslot <keyname>
说明:返回的是一个整数,aaa这个key所在的slot,一个slot里面肯定会有很多个key
127.0.0.1:6530> cluster keyslot aaa
(integer) 10439
#cluster count-failure-reports node-id
说明:该命令返回指定节点的失败报告数量。
192.168.225.130:8200> cluster count-failure-reports
d4f57781dd9979f2a1b9d45f7d8ae66d818989c3
(integer) 0
#cluster countkeysinslot ,slot里面key的数量
127.0.0.1:6511> cluster countkeysinslot 10439
(integer) 1
#cluster getkeysinslot
127.0.0.1:6511> cluster getkeysinslot 10439 10 #说明:10439为slot,10,表示:返回该槽里面的
10个key。返回结果为数组
1) "aaa"
2.2 人工故障转移测试¶
2.2.1 人工故障切换(2节点正常)¶
主:6510,
从:6522
127.0.0.1:6522> cluster failoverok
#状态检查
127.0.0.1:6522>infoReplication
#Replication
role:master
connected_slaves:1
slave0:ip=192.168.9.78,port=6510,state=online,offset=37086,lag=0
2.2.2 人工故障转移(master down)¶
主:6522,
从:6510
127.0.0.1:6510> cluster failover FORCE
ok
#状态检查
127.0.0.1:6510> info Replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.9.78,port=6522,state=online,offset=37086,lag=0
Force选项:
slave节点不和master协商(master也许已不可达),从上如4步开始进行故障切换。当master已不可用,而我们想要
做人工故障转移时,该选项很有用。
但是,即使使用FORCE选项,我们依然需要群集中大多数master节点有效,以便对这次切换进行验证,同时为将成为新
master的salve节点生成新的配置epoch
2.2.3 人工故障转移(忽略一致性验证)¶
主:6510,
从:6522
127.0.0.1:6522> cluster failover TAKEOVER
ok
状态检查
127.0.0.1:6522> info Replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.9.78,port=6510,state=online,offset=38052,lag=1