

一、数据类型介绍¶
1.1 数据类型的分类¶
| 分类名称 | 说明 |
|---|---|
| boolean 数据类型 | PostgreSQL 支持 SQL 标准的 boolean 数据类型。跟 mysql 差异:与 MySQL 中的 bool、boolean 类型相同,占用 1 字节存储空间。 |
| 数值类型 | 整数类型有 2 字节的 smallint,4 字节的 int,8 字节的 bigint;精确类型的小数有 numeric;非精确类型的浮点小数有 real 和 double precision;还有 8 字节的货币(money)类型。与 mysql 差异:无 MySQL 中的 unsigned 整数类型,也无 MySQL 中 1 字节长的 tinyint 整数类型和 3 字节长的 mediumint 整数类型。 |
| 字符类型 | 有 varchar(n)、char(n)、text 3 种类型。与 mysql 差异:PostgreSQL 中的 varchar(n) 最大可以存储 1GB,MySQL 中的 varchar(n) 最大只能量 64KB,PostgreSQL 中的 text 类型相当于 MySQL 中的 longtext 类型。 |
1.2 数据类型的输入与转换¶
些简单的数据类型,如数字或字符串,使用一般的方法输入就可以了,示例如下
select 1, 'hello pg';
复杂的类型转换(带上类型)比如
select int '1' + int '2';
PostgreSQL支持用标准SQL的数据类型转换函数CAST来进行数据类型转换,示例如下
select CAST('5' as int), CAST('2024-03-17' as date);
PostgreSQL中还有一种更简捷的类型转换方式,即双冒号方式,比如
select '5'::int, '2024-03-17'::date;
二、布尔类型¶
boolean的值要么是true(真),要么是false(假),如果是unknown(未知)状态,用NULL表示 可以用不带引号的TRUE或FALSE表示,也可以用其他表示“真”和“假”的带引号字符表示, 如'true'、'false'、'yes'、'no',等等,比如:
-- 创建表
CREATE TABLE t (id int, col1 boolean, col2 text);
-- 插入布尔值测试数据
INSERT INTO t VALUES (1,TRUE, 'TRUE');
INSERT INTO t VALUES (2,FALSE, 'FALSE');
INSERT INTO t VALUES (3,tRue, 'tRue');
INSERT INTO t VALUES (4,fAlse, 'fAlse');
INSERT INTO t VALUES (5,'tRuE', '''tRuE''');
INSERT INTO t VALUES (11,'y', '''y''');
INSERT INTO t VALUES (12,'n', '''n''');
INSERT INTO t VALUES (15,'1', '''1''');
INSERT INTO t VALUES (16,'0', '''0''');
-- 查询:所有 col1 为 false 的数据
select * from t where not col1;
三、数值类型¶
数值类型是最常用的几种数据类型之一,分为整型、浮点型、精确小数等类型
3.1 整数类型¶
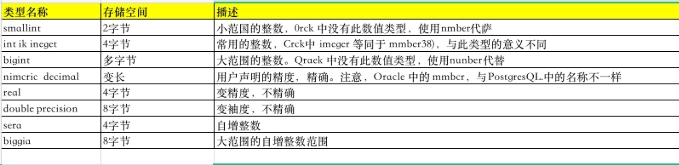
整数类型有3种:smallint、int、bigint
特别注意:PostgreSQL中没有MySQL中的tinyint(1字节)、mediumint(3字节)这两种类型,也没有 MySQL中的unsigned类型
常用的数据类型是int(或integer):因为它提供了在范围、存储空间、性能之间的最佳平衡
什么使用其他两种类型:
smallint类型:一般只有在磁盘空间紧张的时候才使用
bigint类型:只有integer类型的取值范围不够时才用
3.2 精确的小数类型¶
精确的小数类型可用numeric、numeric(m,n)、numeric(m)表示
numeric类型和decimal类型是等效的,这两种类型都是SQL标准,可以存储最多1000位精度的数字,并且可准确地进行计算。它们特别适用于货币金额和其他要求精确计算的场合
优点:可以技术复杂的货币金额以及其他精确度要求很高的场景 缺点:相比于基于整数类型或者下面介绍的浮点数类 型的算术运算,其速度要慢很多
如何声明一个字段的类型为numeric:
NUMERIC(precision, scale) #精度precision必须为正数,标度scale可以为0或者正数
与mysql不同: MySQL中,语法DECIMAL等价于DECIMAL(M,0),M在MySQL中默认为10,PostgreSQL中因作用不大而把它 改成了一个任意精度和标度的数值
案例
create table t1(id1 numeric(3),id2 numeric(3,0),id3 numeric(3,2),id4 numeric);
正常
insert into t1 values(3.1,3.5,3.123,3.123);
#标度,超过小数点位数的标度会自动4舍5入后进行存储
异常
insert into t1 values(3.1,3.5,13.123,3.123);
3.3 序列类型¶
在序列类型中,serial和bigserial与MySQL中的自增字段含义相同。PostgreSQL实际上是通过序列 (sequence)实现的。而MySQL中没有序列
案例:
CREATE TABLE t ( id SERIAL );
等价于:
CREATE SEQUENCE t_id_sequence;
CREATE TABLE t ( id integer NOT NULL DEFAULT nextval('t_id_sequence') );
ALTER SEQUENCE t_id_sequence OWNED BY t.id;
一个表中可否定义多个系列类型?
CREATE TABLE t ( id SERIAL,t_id SERIAL );
3.4 货币类型¶
货币类型可以存储固定小数的货币数目,与浮点数不同,它是完全保证精度的。其输出格式与参数 lc_monetary的设置有关,不同的国家其货币输出格式也不相同,
案例:
show lc_monetary; 查看当前货币配置 SELECT '15.34'::money;
修改货币类型
set lc_monetary = 'en_US.UTF-8'; SELECT '15.34'::money;
说明:money类型占用8字节空间来存储数据,表示的范围为-92233720368547758.08到 +92233720368547758.07
3.5 数学函数和操作符¶
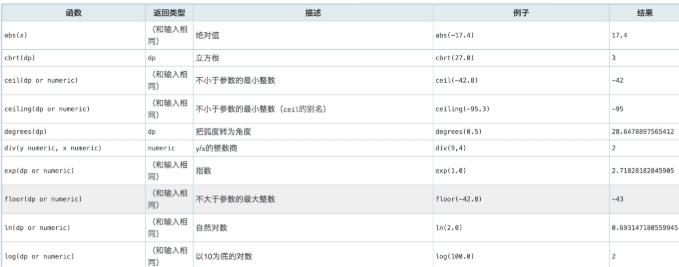
详细介绍:http://postgres.cn/docs/9.5/functions-math.html
四、字符串类型¶
| 类型名称 | 描述 |
|---|---|
| character varying(n) / varchar(n) | 变长,最大为 1GB,存储空间为 4 + 实际的字符长度。与 MySQL 中的 varchar(n) 或 text(n),以及 oracle 中的 varchar2(n) 类似,但是在 MySQL varchar 最长 64 KB,oracle varchar(n) 最长为 4000 字节,而 PostgreSQL 中可以达到 1GB。 |
| character(n) / char(n) | 定长。不足补空白,最大为 1GB,存储空间为 4 + n。 |
| text | 变长。无长度限制。与 MySQL 中的 longtext 相类似。 |
注:varchar(n) 和 char(n) 分别是 character varying(n) 和 character(n) 的别名,未声明长度的 character 等价于 character(1)。
定长的和 character 和 varchar(n) 是否有区别 在 PostgreSQL 中,定长的 character(n) 与 varchar(n) 没有差别。故在大多数情况下,建议使用 text 或 varchar。

案例:http://postgres.cn/docs/9.5/functions-string.html
五、二进制数据类型¶
5.1 什么是二进制类型¶
PostgreSQL中只有一种二进制类型:bytea类型。此数据类型允许存储二进制字符串,对应MySQL和Oracle中 的blob类型。Oracle中的raw类型也可以用该类型取代
二进制字符串和字符串类型的区别:
1、二进制字符串完全可以存储字节零值,以及其他 “不可打印”的字节
2、对二进制字符串的处理实际上就是 对字节的处理,而对字符串的处理,则取决于区域设置
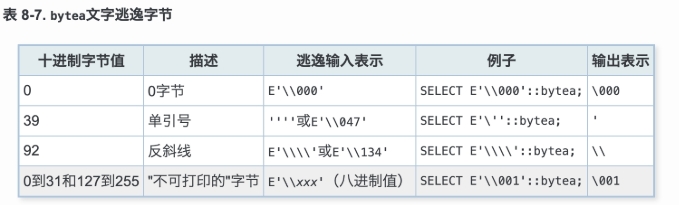
5.2 二进制数据类型转义表示¶
既然二进制字符串中的部分字符为不可打印字符,那么如何在SQL语句的文本串中输入bytea数值呢?答案是 使用转义。通常来说,要转 义一个字节值,需要把它的数值转换成对应的三位进制数,并且加两个前导反斜杠。有些八进制数值可以加一 个反斜杠直接转义,比如单引号和反斜杠本身
六、位串类型¶
位串类型是可以存放一系列二进制位的类型,相对于二进制类型来说,此类型在做一些位操作更方便、更直观 位串就是一串由1和0组成的字符串。PostgreSQL中可以直观地显式操作二进制位。下面是两种SQL位类型
bit(n)
试图存储短一些或者长一些的数据都是错误的
其中n是一个正整数
bit varying(n)
最长为n的变长类型,更长的串会被拒绝
6.1 位串类型的使用方法¶
CREATE TABLE test (a BIT(3), b BIT VARYING(5));
INSERT INTO test VALUES (B'101', B'00');
INSERT INTO test VALUES (B'10', B'101');
INSERT INTO test VALUES (B'11110', B'101');
七、日期/时间类型¶
7.1 日期类型¶
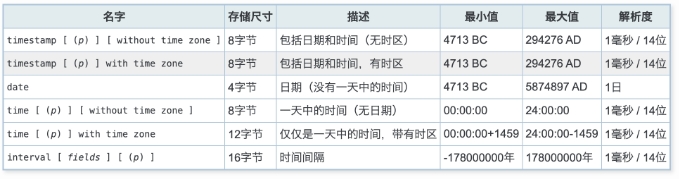
7.2 日期输入¶
语法格式:type [ (p) ] 'value'
日期和时间的输入几乎可以是任何合理的格式,包括ISO-8601格式、SQL-兼容格式、传统的Postgres格式及 其他形式
示例:
create table t(col1 date);
insert into t values(date '12-10-2010');
select * from t;
show datestyle;
set datestyle='YMD';
insert into t values(date '2010-12-11');
set datestyle='YDM';
insert into t values(date '2010-12-11');
7.2.1 时间输入¶
输入时间时需要注意时区的输入。time被认为是time withouttime zone的类型,这样即使字符串中有时区也会 被怱略
实例:
select time '04:05:06';
select time '04:05:06 PST';
select time with time zone'04:05:06 PST';
时间字符串可以使用冒号作分隔符,即输入格式为 “hh:mm:ss”,如“102345”,也可以不用分隔符,如102345”表示10点23分45秒
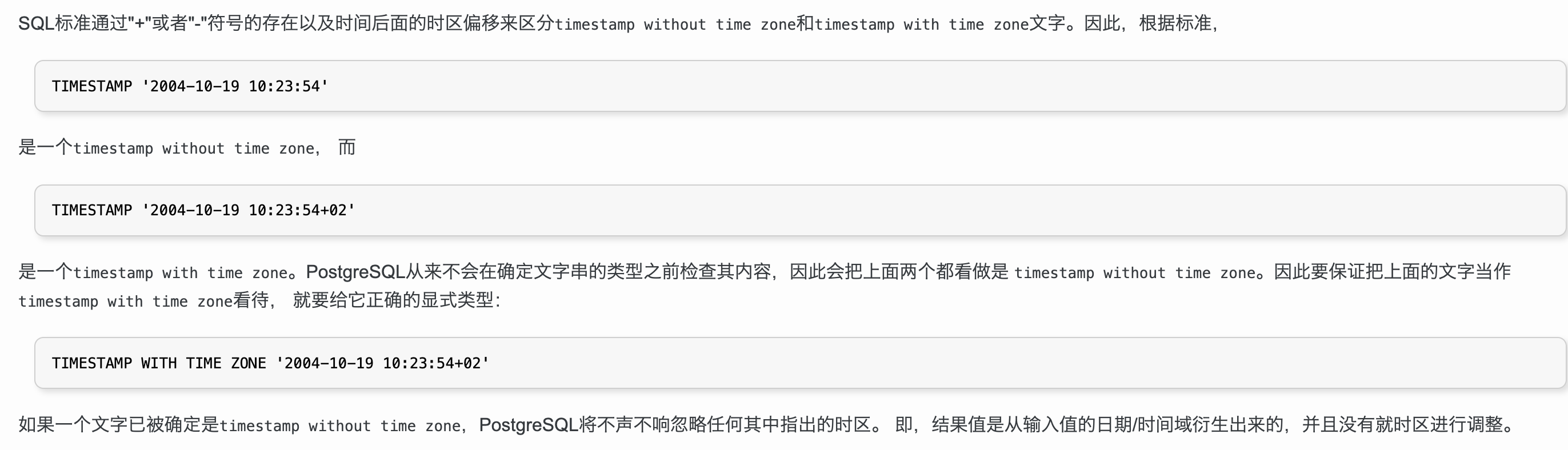
详细参考: http://postgres.cn/docs/9.5/datatype-datetime.html
7.3 时间函数¶
PostgreSQL提供了许多返回当前日期和时间的函数。
-- 当前日期
SELECT CURRENT_DATE;
-- 当前时间(带时区)
SELECT CURRENT_TIME;
SELECT CURRENT_TIME(3); -- 保留3位毫秒
-- 当前时间戳(带时区)
SELECT CURRENT_TIMESTAMP;
SELECT CURRENT_TIMESTAMP(3);
-- 当前时间(不带时区)
SELECT LOCALTIME;
SELECT LOCALTIME(3);
-- 当前时间戳(不带时区)
SELECT LOCALTIMESTAMP;
SELECT LOCALTIMESTAMP(3);
说明: CURRENT_TIME和CURRENT_TIMESTAMP传递带有时区的值;LOCALTIME和LOCALTIMESTAMP传递的值不 带时区
CURRENT_TIME、CURRENT_TIMESTAMP、LOCALTIME和 LOCALTIMESTAMP可以有选择地接受一个精度 参数, 该精度导致结果的秒域被园整为指定小数位。如果没有精度参数,结果将被给予所能得到的全部精度
案例:
SELECT CURRENT_TIME;
SELECT CURRENT_DATE;
SELECT CURRENT_TIMESTAMP;
SELECT CURRENT_TIMESTAMP(2);
SELECT LOCALTIMESTAMP;
问题:如果函数是在事务里会是什么表现 案例
begin;
SELECT CURRENT_TIMESTAMP;
SELECT CURRENT_TIMESTAMP;
解释:这些函数全部都按照当前事务的开始时刻返回结果,所以它们的值在事务运行的整个期间内都不改变。 我们认为这是一个特性:目的是为了允许一个事务在"当前"时间上有一致的概念
如果想实时返回时间呢,不想在事务里控制:
PostgreSQL同样也提供了返回当前语句开始时间的函数, 它们会返回函数被调用时的真实当前时间。这些非 SQL 标准的函数列表如下
-- 事务开始时间(整个事务中不变)= CURRENT_TIMESTAMP
SELECT transaction_timestamp();
-- 当前语句开始时间(单条SQL内不变)
SELECT statement_timestamp();
-- 真实当前时间(SQL执行中会变化)
SELECT clock_timestamp();
-- 同 clock_timestamp(),返回字符串格式
SELECT timeofday();
-- 最常用 = transaction_timestamp()
SELECT now();
八、枚举类型¶
枚举类型是包含一系列有序的静态值集合的一个数据类型,等于某些编程语言中的enum类型 但是与MySQL不一样,在PostgreSQL中要使用枚举类型需要先使用CREATE TYPE来创建此枚举类型
案例:
CREATE TYPE week AS ENUM ('Sun','Mon','Tues','Wed','Thur','Fri', 'Sat');
需要先声明
CREATE TABLE duty(person text, weekday week); INSERT INTO duty values('张三', 'Sun');
INSERT INTO duty values('李四', 'Mon'); INSERT INTO duty values('王二', 'Tues'); INSERT
INTO duty values('赵五', 'Wed');
查询:SELECT * FROM duty WHERE weekday = 'Sun';
输入的字符串不在枚举类型之间
SELECT * FROM duty WHERE weekday = 'Sun.'; (会报错)
怎么查看当前枚举类型
\dT+ week
select * from pg_enum;
如何修改枚举类型值:
alter TYPE week add value 'Sat';
alter TYPE week rename value 'Sat' to 'Sata';
如果要删除枚举类型:
-- 1. 将原有枚举改名
ALTER TYPE "public"."week" RENAME TO "week2";
-- 2. 创建同名枚举类型(新值)
CREATE TYPE week AS ENUM ('START');
-- 3. 修改拥有者
ALTER TYPE "public"."week" OWNER TO "postgres";
-- 4. 如果字段有默认值,先删除
ALTER TABLE "order" ALTER COLUMN status DROP DEFAULT;
-- 5. 修改字段枚举类型(关键转换)
ALTER TABLE "public"."order"
ALTER COLUMN "status" TYPE "week"
USING "status"::text::week;
-- 6. 重新设置默认值
ALTER TABLE "order" ALTER COLUMN status SET DEFAULT 'START';
-- 7. 删除旧枚举
DROP TYPE "public"."week2";
九、几何类型¶
9.1 几何类型介绍¶
PostgreSQL数据库提供了点、线、矩形、多边形等几何类型,其他数据库大都没有这些类型,可以说是pg独 有的
PostgreSQL主要支持一些二维的几何数据类型。最基本的类型是“point”,
几何类型:
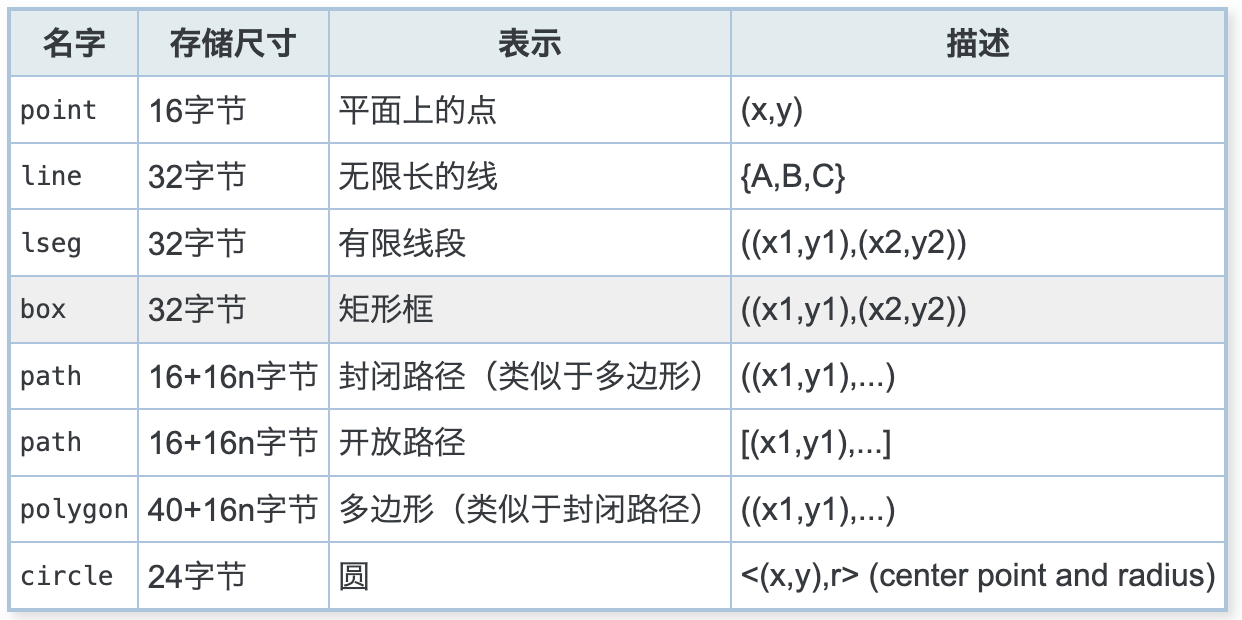
案例:
select '1,1'::point;
select lseg '(1,1),(2,2)';
select '1,1,2,2'::lseg;
9.2 几何类型的操作符¶
PostgreSQL提供了丰富的几何类型操作符
·+:平移
·-:平移
·*:缩放/旋转
·/:缩放/旋转
#:对于两个线段,计算出交点,而对于两个矩形,计算出相关的矩形
#:对于路径或多边形,则计算出顶点数
@-@:计算出长度或周长
@@:计算中心点
##:第一个和第二个操作数的最近点
<->:计算间距
&&:是否重叠,有一个共同点为
案例:
对于点与点之间,相当于把点看成一个复数,点和点之间的加减乘除相当于两个复数之间的加减乘除,示例如下
平移运算符
select point '(1,2)' + point '(10,20)';
select point '(1,2)' - point '(10,20)';
缩放/旋转运算符
select point '(1,2)' * point '(10,20)';
select point '(1,2)' / point '(10,20)';
对于矩形与点之间,示例如下
select box '((0,0),(1,1))' + point '(2,2)'; …………
其他详见:http://postgres.cn/docs/9.5/functions-geometry.html
十、网络地址类型¶
PostgreSQL为IPv4、IPv6以及以太网MAC地址都提供了特有的类型,使用这些类型存储IP地址、MAC地址相 对于用字符串存储这些类型来说,不容易产生歧义
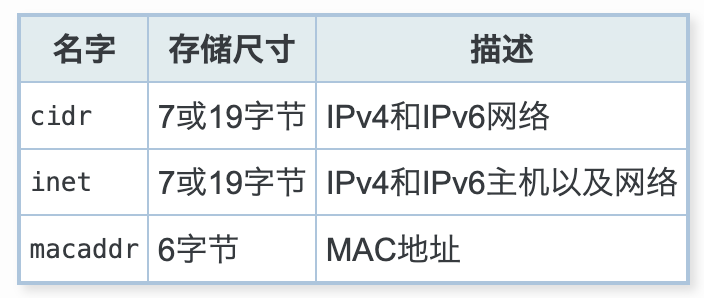
10.1 inet 与 cidr 类型¶
inet和cidr类型都可以用于存储一个IPv4或IPv6的地址,示例如
select '192.168.1.100'::inet; select '192.168.1.100'::cidr;
inet与cidr的区别 对于inet来说,如果子网掩码是32并且地址是IPv4,那么它不表示任何子网,所表示的只是一台主机的地址 而cidr总是显示出掩码,cidr总是对地址与掩码之间的关系
select '192.168.1.100/16'::inet;
10.2 macaddr 类型¶
macaddr类型用于存储以太网的MAC地址,可以接受多种自定义格式,示例如下
'00:e0:4c:75:7d:5a'
'00-e0-4c-75-7d-5a'
'00e04c-757d5a'
'00e04c:757d5a'
'00e0.4c75.7d5a'
'00e04c757d5a'
输出总是上面的第一种形式 例如:
select '00e04c757d5a'::macaddr;
select '00e04c:757d5a'::macaddr;
select '00-e0-4c-75-7d-5a'::macaddr;
10.3 网络地址类型的操作符¶
cidr 和 inet 操作符
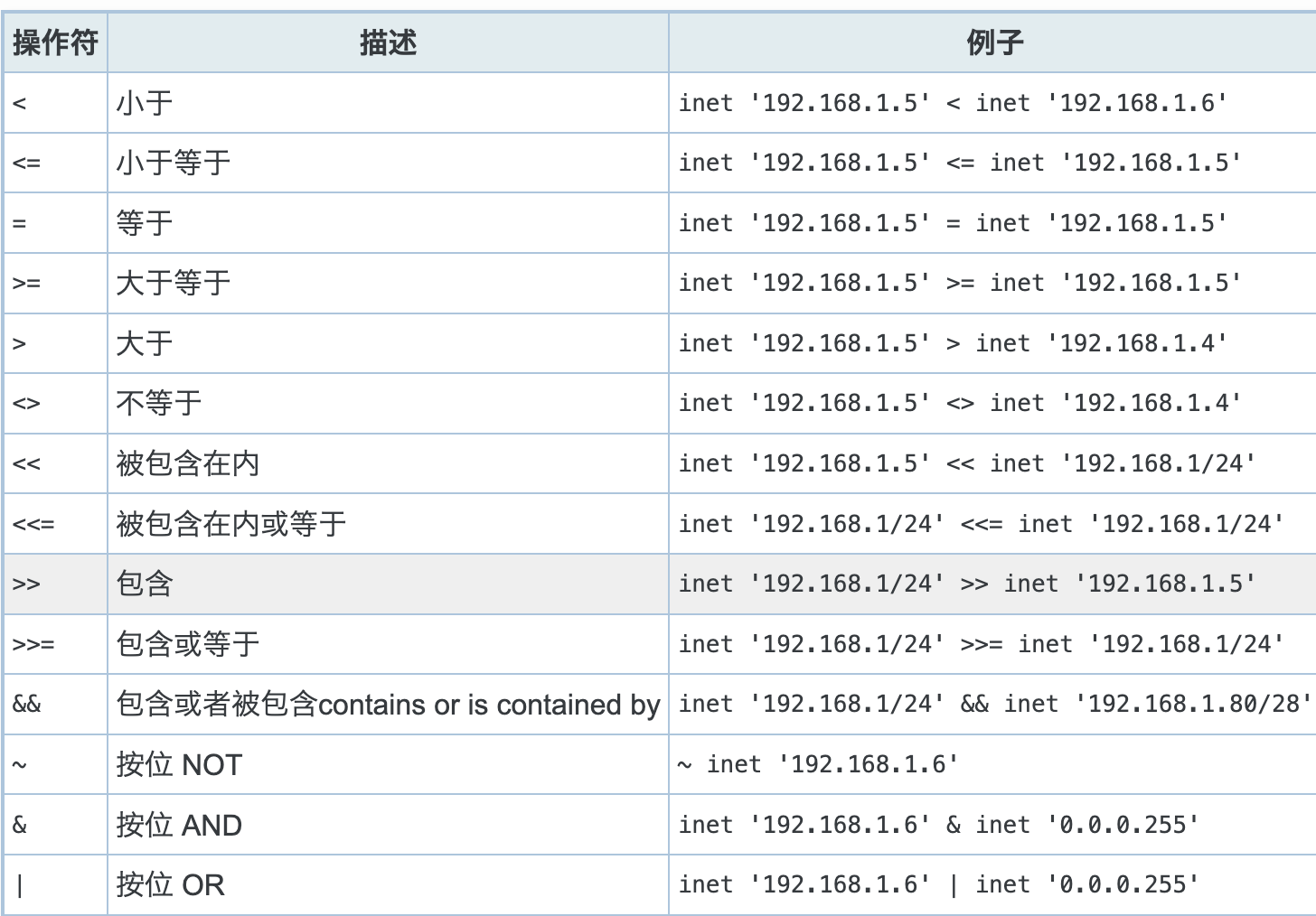
cidr 和 inet 函数

详见: http://postgres.cn/docs/9.5/functions-net.html
十一、复合类型¶
PostgreSQL中可以如C语言中的结构体一样定义一个复合类型
示例1,定义一个复数类型
CREATE TYPE person AS (
name text,
age integer,
sex boolean );
创建复合类型的语法类似于
CREATE TABLE,只是这里只能声明字段名字和类型,目前不能声明约束(比如NOT NULL)
11.1 根据复合类型创建表¶
CREATE TABLE capacitance_test_data(
test_time timestamp,
student person);
11.2 复合类型的输入¶
格式:'( val1 , val2 , ... )'
案例:
CREATE TYPE person AS ( name text, age integer, sex boolean );
CREATE TABLE author( id int, person_info person, book text );
insert into author values( 1, '("张三",29,TRUE)', '张三的自 传');
如果有一字段要传空,的位置上就不要写任何字符:比如
insert into author values( 2, '("张三",,TRUE)', '张三的自传');
11.3 访问复合类型¶
可否这样?select person_info.name from author;
select (person_info).name from author;-- 需要加上圆括号
11.4 修改复合类型¶
insert into author values( ('张三', 29, TRUE), '自传');
UPDATE author SET person_info = ROW('李四', 39, TRUE) WHERE id =1;
UPDATE author SET person_info = ('王二', 49, TRUE) WHERE id =2;
十二、xml 类型¶
xml类型可用于存储XML数据。使用字符串类型(如text类型)也可以存储XML数据,但text类型不能保证其中 存储的是合法的XML数据
注意,要使用xml数据类型,在编译PostgreSQL源码时必须使用以下参数:
configure --with-libxml
xml输入案例:
select xml '<osdba>hello world</osdba>';
select '<osdba>hello world</osdba>'::xml;
详解:http://postgres.cn/docs/9.5/datatype-xml.html
十三、JSON 类型¶
JSON数据类型可以用来存储JSON(JavaScript Object Notation)数据,而JSON数据格式是在RFC 4627中定义的。当然也可以使用text、varchar等类型来存储 JSON数据,但使用这些通用的字符串格式将无法自动检测字符串是否为合法的JSON数据。
13.1 JSONB¶
JSON数据类型是从PostgreSQL9.3版本开始提供的,在9.3版本中只有一种类型JSON,在PostgreSQL9.4版 本中又提供了一种更高效的类型JSONB
13.2 json 与 jsonb 的区别¶
JSON类型是把输入的数据原封不动地存放到数据库中,使用时需要重新解析数据 JSONB类型是在存储时就把JSON解析成二进制格式,使用时就无须再次解析,所以,JSONB在使用时性能会 更高
JSONB支持在其上建索引,而JSON则不支持,这是JSONB类型一个很大的优点
13.3 json 类型简单案例¶
select '9'::json, '"osdba"'::json, 'true'::json, 'null'::json;
select json '"osdba"', json '9', json 'true', json 'null';
用JSONB案例:
select jsonb '"osdba"', jsonb '9', jsonb 'true', jsonb 'null';
JSON中使用数组的示例如下:
SELECT '[9, true, "osdba", null]'::json, '[9, true, "osdba", null]'::jsonb;
使用字典的示例如下:
SELECT json '{"name": "osdba", "age": 40, "sex": true, "money" : 250.12}';
13.3.1 JSON 函数和操作符¶
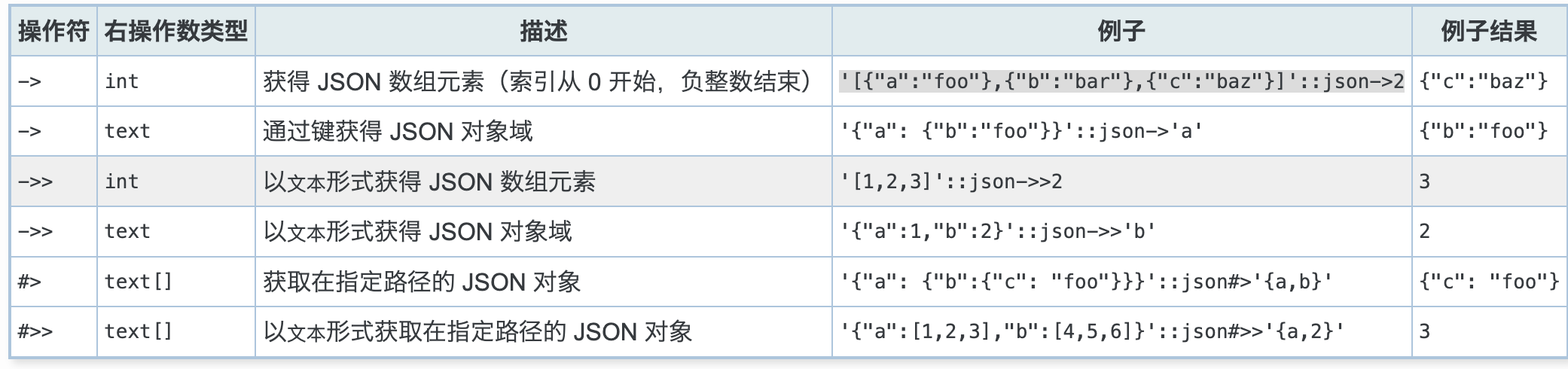
案例详解:http://postgres.cn/docs/9.5/functions-json.html
十四、Range 类型¶
PostgreSQL数据库中特有的数据类型:Range类型, 此类型可以进行范围快速搜索,因此在一些场景中非常有用
14.1 range 类型有什么用处?¶
直接用开始值和结束值来表示,还要造一个Range类型? 案例:
假设我们有以下需求,某个IP地址库中记录了每个地区的IP地址范围,现在需要查询客户的IP地址属于哪个地区。该IP地 址库的定义如下
CREATE TABLE ipdb1( ip_begin inet, ip_end inet, area text, sp text);
如果我们要查询的是IP地址“115.195.180.105”属于哪个地区,SQL语句如下:
select * from ipdb1 where ip_begin <= '115.195.180.105'::inet and ip_end >= '115.195.180.105'::inet;
有什么问题?全表扫描,性能很差 可以在ip_begin和ip_end上建索引
create index idx_ipdb_ip_start on ipdb1(ip_begin); create index idx_ipdb_ip_end on ipdb1(ip_end);
查看执行计划:
explain analyze verbose select * from ipdb1 where ip_begin <= '115.195.180.105'::inet and ip_end >= '115.195.180.105'::inet; QUERY PLAN
在PostgreSQL中,上面的SQL查询可以使用到这两个索引,但都是分别扫描两个索引建位图,然后通过位图 进行AND操作
所以对索引进行范围扫描效率仍不太高
有没有更方便的方式:这就是使用Range类型
首先,创建类似的IP地址库表:
CREATE TYPE inetrange AS RANGE (subtype = inet); CREATE TABLE ipdb2( ip_range inetrange, area text, sp text);
insert into ipdb2 select ('[' || ip_begin || ',' || ip_end || ']') ::inetrange, area, sp from ipdb1;
然后创建GiST索引:
CREATE INDEX idx_ipdb2_ip_range ON ipdb2 USING gist (ip_range);
接下来就可以使用包含运算符“@>”来查找相应的数据了:
select * from ipdb1 where ip_range @> '115.195.180.105'::inet; 可以查看执行计划:explain analyze verbose select * from ipdb2 where ip_range @> '115.195.180.105'::inet;
十五、数组类型¶
PostgreSQL支持表的字段使用定长或可变长度的一维或多维数组,数组的类型可以是任何数据库内建的类 型、用户自定义的类型、枚举类型及组合类型。
案例:
CRETE TABLE testtab04(id int, col1 int[], col2 int[10], col3 text[]);
15.1 如何输入数组值¶
create table testtab05(id int, col1 int[]);
insert into testtab05 values(1,'{1,2,3}');
insert into testtab05 values(2,'{4,5,6}');
select * from testtab05;
15.2 如何访问数组类型¶
create table testtab08(id int, col1 text[]);
insert into testtab08 values(1,'{aa,bb,cc,dd}');
insert into testtab08 values(2,'{ee,ff,gg,hh}');
select * from testtab08;
select id, col1[1] from testtab08;
15.3 其他类型¶
1、UUID类型
2、pg_lsn类型
3、伪类型