

一、pg standby的原理¶
利用主库产生的wal文件,通过流复制方式,存在一个与主库同步的在线备数据库服务器,
-
当主数据库服务器失败后,备数据库服务器可以快速提升为主服务器并提供服务,从而实现数据库服务的 高可用
-
备数据库服务器也提供了数据库的另一个副本,当主数据库服务器的数据丢失后,备数据库服务器上还有 一份数据,不会导致数据的完全丢失,从而提高数据的可靠性
-
允许多台数据库服务器同时提供负载均衡服务。因为数据库内部记录的是数据,多台数据库同时提供服务 时,提升整个数据库吞吐能力,standby主要用来实现读拓展
二、搭建Standby数据库的步骤¶
搭建主备最简单的方式就是主库停机,然后拷贝一份备份到备库,配置相关复制信息再启动,但是一般情况 下,不允许停机操作,所以 PostgreSQL也提供了热备份的方式搭建Standby备库,即在主库不停机,也不终止正常读写的情况下,就可以 在线搭建Standby备库。
过程可分为以下两个大步骤
-
第一步:通过在线热备份的方式生成一个基础备份,并把生成的基础备份传到备机上
-
第二步:在备库上配置相关配置文件后,把备库启动在Standby模式下,这样就完成了Standby库的搭建
三、异步流复制Hot Standby¶
3.1 主数据库的配置¶
pg_hba.conf 增加如下配置
host replication all 0/0 md5 允许任意用户从任何网络(0/0)网络上发起到本数据库的流复制连接,使用MD5的密码认证。
postgresql.conf设置几个参数
listen_addresses = '*'
max_wal_senders = 10
把max_wal_senders参数设置成一个大于零的值
wal_level = replica
min_wal_size = 800MB
min_wal_size参数的默认值为“80MB”,该值通常太小,
很容易导致备库失效
3.2 在Standby上生成基础备份¶
执行
pg_basebackup -h 主库ip -U rep -F p -P -X stream -R -D /var/lib/pgsql/15/data -l osdbabackup201912151110
因为跟上了 -R 所以也会生成 standby.signal文件,同时在postgresql.auto.conf中生成复制内容 如果没有加“-R”参数 手动添加上面内容即可
3.3 启动standby¶
启动之前 需要注意几个参数
hot_standby”是否为“on”,设置该参数是为了让备库是HotStandby,即可以对外提供只读服务 新版本中默认开启了
3.4 查看流复制是否正常¶
主库查看:
select client_addr,state,sync_state from pg_stat_replication; state 为streaming时 表示复制正常
如果执行如下命令看不到信息或者 state 不为streaming时 ,复制搭建是不正常的,需要查看 查看方法,去查看备库中的错误信息,比如如下报错,很可能就是用户密码不正确,可以尝试用用户密码连接主库试试
FATAL: could not connect to the primary server: FATAL: password authentication failed for user "osdba
如果出现如下错误,这通常是主库上的pg_hba.conf文件中缺失了允许流复制连接的配置
FATAL: could not connect to the primary server: FATAL: no pg_hba.conf entry for replication connection from host "ip", user "postgres", SSL off
3.5 测试数据¶
在主库创建库和表,以及写数据,验证备库是否能查询到
create table test01(id int primary key, note text); insert into test01 values(1,'11111');
insert into test01 values(2,'22222');
3.6 交换主备库的角色(正常切换)¶
对于PostgreSQL数据库来说,切换操作的步骤比较简单,分为如下几步
-
先停主库,再停备库
-
在原主库的数据目录中建文件“standby.signal”配置连接新主库的流复制参数
-
把原备库数据目录下的文件“standby.signal”重命名或直接删除
-
启动原备库,这时该备库变成了主库
-
启动原主库,这时该主库变成了备库
3.7 故障切换¶
异步复制时,如果主库出现了问题,可以激活备库作为主库提供服务,执行命令很简单,在备库执行如下命令 即可
pg_ctl promote
这种情况,一般情况主库出现问题后,通常这些故障可能会导致数据丢失,如宕机、机器重启的故障等 当故障解决之后,我们会把原主库转换成新主库的Standby备库,该转换一般来说需要重新搭建备库。这是因 为原主库的一些数据没有同步过去就把备库激活了,备库相当于丢失了一些数据。而重新搭建备库的话 一般情况就是重新做一个数据同步,把新的主库当成备库,但是如果数据库很大,基础备份会执行很长时间
那有没有更好的办法
PostgreSQL 9.5版本开始提供pg_rewind命令 不需要复制太多的数据就可以把原主库转换成新主库 的备库。该命令相当于把原主库的数据“回滚”到新主库激活时的状态
使用pg_rewind命令的限制 必须把参数“wal_log_hints”设置成“on”
pg_rewind执行命令(在原主库执行)
pg_rewind -D $PGDATA --source- server='host=ip user=postgres password=postgres'
如果执行报如下错误,需要重启一下旧主库的pg
pg_rewind: fatal: target server must be shut down cleanly
pg_rewind之后 需要手动在旧主库数据目录下面建文件“standby.signal“ 在 postgresql.auto.conf 配置
primary_conninfo = 'user=rep password=rep123 host=新主库ip port=5432 sslmode=prefer sslcompression=0'
注意: 一定要先建好standby.signal再启动数据库,否则启动了数据库就会进入主库模式。如果这样做了,需要把数 据库停下来,重新运行pg_rewind命令
四、同步流复制的Standby数据库¶
异步流复制有一个明显的缺点:
当主库损坏的时候,激活备库后 可能会丢失一些数据,这对于一些不允许丢失数据的应用来说是不可接受的
pg9.2版本引入了 同步流复制的功能 解决了主备库切换时丢失数据的问题。同步复制要求WAL日志写入Standby数据库后commit才能返回,所以也引入了一个问题:
Standby库出现问题时,会导致主库被hang住
如果要使用同步流复制时,如果解决这个问题?解决这个问题的方法是启动两个Standby数据库,这两个Standby 数据库只要有一个是正常运行的就不会让主库hang住。所以在实际应用中,同步流复制,总是有一个主库和两个以上的Standby备库
在同步复制中,如果主库发生临时故障激活了其中一个备库,要想把原主库转换成新主库的备库,仍然需要用 pg_rewind处理一下才行
4.1 同步复制的配置¶
同步复制的配置主要是在主库上配置参数
synchronous_standby_names
可以指定多个 指定多个Standby的名称 而Standby名称是在Standby连接到主库时由连接参数“application_name”指定的
比如synchronous_standby_names的配置
synchronous_standby_names='s1,s2,s3' 只有第一个备库s1是同步的,其他均是潜在的同步备库,即只要WAL日志传递到第一个备库s1,事务commit就可以返回 了,当第一个备库s1出现问题时,第二个备库s2才会提升为同步备库
synchronous_standby_names='2 (s1,s2,s3) WAL日志必须传到前两个备库“s1”和“s2”,事务commit才可以返回
synchronous_standby_names='ANY 2(s1,s2,s3)' 只要WAL日志传到了任意两个备库,事务commit就可以返回了
影响同步流复制的还有另一个参数
synchronous_commit
remote_apply:WAL日志被传到备库并被apply,事务commit才返回
on:WAL日志被传到备库并被持久化(不必等其被apply),事务commit才返回
remote_write:WAL日志被传到备库的内存中(不必等其被持久化),事务commit才返回
local:WAL日志被本地持久化后(不用管远程)事务commit就可以返回
off:不必等WAL日志被本地持久化,也不管是否传到远程,事务commit都可以立即返回
针对同步的流复制synchronous_commit的可选值如下
on
remote_apply
remote_write
4.2 同步复制的配置案例(一主2备)¶
4.2.1 第一步:主库配置¶
主备的pg_hba.conf配置
host replcation rep 0.0.0.0 md5
主库 postgresql.conf 配置
max_wal_senders=10
wal_level=hot_standby
synchronous_standby_names='standby1,standby2'
其中 'standby1,standby2' 就是在Standby数据库中配置连接参数“application_name”时指定的名称 synchronous_standby_names 可以先配置不需要重启主库
4.2.2 第二步:备库“pg01”上的配置¶
在postgresql.auto.conf中配置如下(primary_conninfo”中增加连接参数“application_name”)
primary_conninfo='application_name=standby1
user=rep password=rep123 host=主库ip port=5432 sslmode=disablesslcompression=1'
启动pg01
4.2.3 第三步:备库“pg02”上的配置¶
在postgresql.auto.conf中配置如下(primary_conninfo”中增加连接参数“application_name”)
primary_conninfo='application_name=standby2
user=rep password=rep123 host=主库ip port=5432 sslmode=disablesslcompression=1'
启动pg02
4.2.4 第四步:在主库上启动同步复制¶
pg_ctl reload -D /home/osdba/pgdata
查看同步的状态:
select application_name,client_addr,state, sync_priority, sync_state from pg_stat_replication;
sync_priority 这里有两个值
sync:表示这个standby是同步库
potential:表示这个standby是潜在的同步库
这种架构下,当sync的standby宕机后,potential的standby会升级为sync 整个主库是不会受到影响的
思考问题
1、两个备库的情况下 配置参数为 synchronous_standby_names='standby1,standby2' 如果两个standby宕机了,会怎么样?
主库执行事务会卡住
2、3个备库的情况下 配置参数为 synchronous_standby_names=' standby1,standby2,standby3' 如果两个standby宕机了,会怎么样?
主库执行事务不会受到影响
3、如果配置为 synchronous_standby_names='2 (standby1,standby2,standby3)' 如果两个standby宕机了, 会怎么样?
主库执行事务会卡住
五、检查主备高可用复制状态¶
5.1 检查流复制情况是否正常¶
主库上的视图 pg_stat_replication
select pid,state,client_addr, sync_priority,sync_state from pg_stat_replication; 如果 state 不为streaming 就表明对应的复制异常
备库上的视图pg_stat_wal_receiver来查看流复制的状态: 其中 status:状态,只有“streaming”是正常状态 还有几个字段需要我们了解的
receive_start_lsn:WAL接收进程启动时使用的第一个WAL日志的位置。 receive_start_tli:WAL接收进程启动时使用的第一个时间线编号。 received_lsn:已经接收到并且已经被写入磁盘的最后一个WAL日志的位置。 received_tli:已经接收到并且已经被写入磁盘的最后一个WAL日志的时间线编号。 last_msg_send_time:接收到最后一条WAL日志消息后,向主库发回确认消息的发送时间。
5.2 监控主备延迟¶
同步流 制和异步流 备库之间的延迟是客观存在的 ,事实 流复制主库、库机器负载较低的情况下 备延迟通常能 在秒级,数据库越忙或据库主机负载越高主备延迟越,有两个维度衡量主备库之间的延迟:
-
通过 WAL 延迟时间衡量
-
通过 WAL日志应用延迟
5.2.1 通过 WAL 延迟时间衡量¶
WAL 的延迟分为 write延时,flush replay 延时, 别对 pg_stat_replication表中的 write_lag,flush_lag replay_lag ,
write_lag:主库上 WAL日志落盘 等待备库接受WAL 志(这时 WAL 日志流还没写人备 WAL日志件,还在操作系统缓 存中)并返回确认信息的时间
flush_lag: 主库 WAL日志落盘 等待备库接 WAL 日志(这时 WAL 日志流已写入备的WAL 文件 但还没 应用 WAL) 并返回确认信息的时间
replay_lag: 主库上 WAL 志落盘 等待备库接 WAL (这时 WAL 日志流已写入 WAL 日志文件, 并且已用于 WAL 志)并返回确认信息的时间
对于一个有稳定写事务的数据库,备库库收到主 库发送的 WAL 日志流后首先 写人备 库主机操作系统缓存,之后写人 WAL 日志文件, 备库根据 WAL 日志文件应用日 志,因此这种场景下 write_lag flush_lag replay_ lag 大小关系如下所示: replay_lag > flush_lag > write_lag
或者通过:
SELECT EXTRACT (SECOND FROM now() pg_last_xact_replay_timetamp ()); datepart
这种情况就表示没有延迟,缺点是如果主库上只有读操作,主库不会发送 WAL 日志流到 备库,这时这种情况 来判断旧不严谨,会存在误判
5.2.2 通过 WAL 日志应用延迟量衡量¶
通过流复制备库 WA 应用位置和主库本地 WAL 写入位置之间的 WAL 志量能够 准确判断主备延时伞,在流复制主库执行以下 SQL
SELECT pid, usename , client_addr, state ,
pg_wal_lsn_diff(pg_current_wal_lsn() , write_lsn ) write_delay,
pg_wal_lsn_diff(pg_current_wal_lsn() ,flush_lsn) flush_delay ,
pg_wal_lsn_diff(pg_current_wal_lsn() , replay_lsn) replay_delay
FROM pg_stat_replication ;
pg_current_wal_lsn 函数显示流复制主库当前 WAL 日志文件写人的位置, pg_wal_lsn_ diff 算两个 WAL 日志位置之间的偏移 ,返回单位为字节数,以上内容显示流复制
wrte_delay:表示示流复制备库 WAl的 writ 延迟多少字节
flush_lsn:flush 延迟多少字节
replay_dely:replay多少字节
这种方式有个缺点,当主库若掉时, 方法行不通
5.2.3 通过创建主备延时测算表方式¶
这种方法在主库上创建一张主备延时测算表,并定时往表插入数据或更新数据,之后在备库上计算这条记录的 插时间或更新时间与前时间的异来判断主备延时,这种方法不是很严谨,但很实用,当主库若机时,这种方式 依然可以大概判断出主备延时
5.3 延迟备库¶
流复制主库提交事务后,主库会将此事务的 WAL 日志流发送给备库,备库接WAL 日志流后进行重做,这个操作 通常瞬间完成,延迟的备库实际上是设置备库延迟重WAL 的时间,而备库依然及时接收主库发送的 WAL 日志流 ,只是不是一 接收到 WAL后就立即重做,而是等待设 的时间再做,假如设参数为一分钟,流复制备库接收到主库发送 WAL 日志流后需等待一分钟才重做
设置参数就是
recovery_min_apply_delay (integer)
支持单位:
ms 毫秒
s 秒
min 分钟
h 小时
d 天
比如设置延迟standby 为1天
recovery_min_apply_delay=1d
然后按备库的搭建,重启备库即可完成延迟备库的的搭建
5.4 级联复制¶
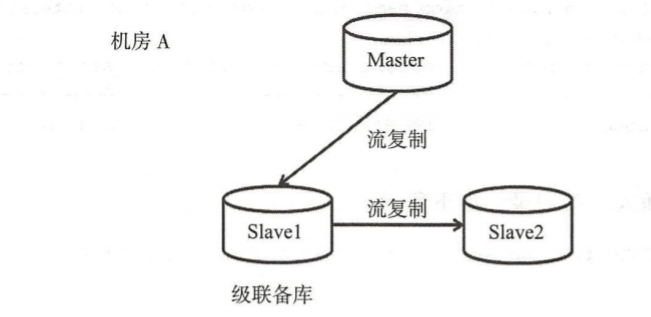
slave2 备库不是直连 Master库,而是连接到 slave1 备库, slave1 备库一方面接收来自 Master 发送的 WAL 日志,另一方面将 WAL 日志发送给 slave2 备库,将既接收 WAL 同时又发送 WAL 的备库称为级联备库( cascading standby ),这里 slave1 就是级联备库
级联复制搭建也比较简单,直接把slave2的 host写成slave1的地址即可