

一、pxc原理¶
Postgres-XC是基于PostgreSQL数据库实现的真正的数据水平拆分的分布式数据库,它与目前市面上大多数的 数据水平拆分方案不同的是,大多数数据水平拆分方案都有很多限制,如不能跨机器Join,对SQL也有各种各 样的使用限制,而Postres-XC实现得更彻底,用户访问 Postgres-XC集群,就像访问单机数据库一样,基本没有太大的差别
1.1 Postgres-XC的特点:¶
-
与大多数数据水平拆分方案一样,把表的数据通过HASH算法切片到各台机器上
-
基于PostgreSQL实现的集群:可以使用PostgreSQL的客户端及驱动无差别地连接到Postgres-XC上。客 户端与PostgreSQL是完全兼容的
-
并不是架构在PostgreSQL数据库之上的中间件:是通过修改PostgtreSQL源代码实现的数据库集群,并不 是一些架构在数据库之上的中间件,实现了全局事务,是数据强一致性的
-
对称集群:无中心节点,SQL可以发送给任意一台协调器,可扩展性比较好,应用可以读写任意节点,结 果都是一样的
-
线性扩展读和写:与读写分离的方案不同的是,通过增加节点,不仅可以扩展读还能扩展写的性能。
二、Postgres-XC的性能¶
理想情况下,我们认为,分布式数据库 n个数据节点的 性能是单机性能的n倍,但实际并不是这样,也没有哪种分布式数据库可以做到
pxc的性能是怎么压的:
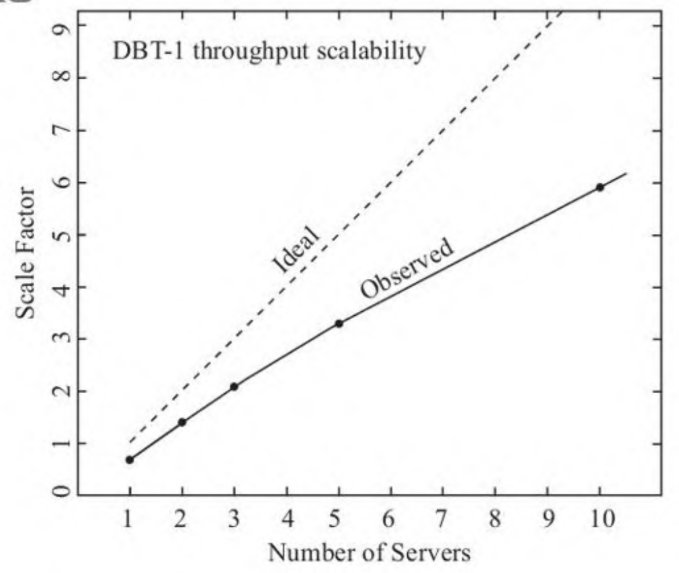
当有3个Postgres-XC数据节点时,可达到单个PostgreSQL数据库2倍的性能,5个节点可以达到单个 PostgreSQL数据库3倍的性能,10个Postgres-XC数据节点时,基本可以到达单个PostgreSQL数据库6倍的性 能,而且
随数据节点的增加,Postgres XC的可扩展能力的增长还是比较线性的
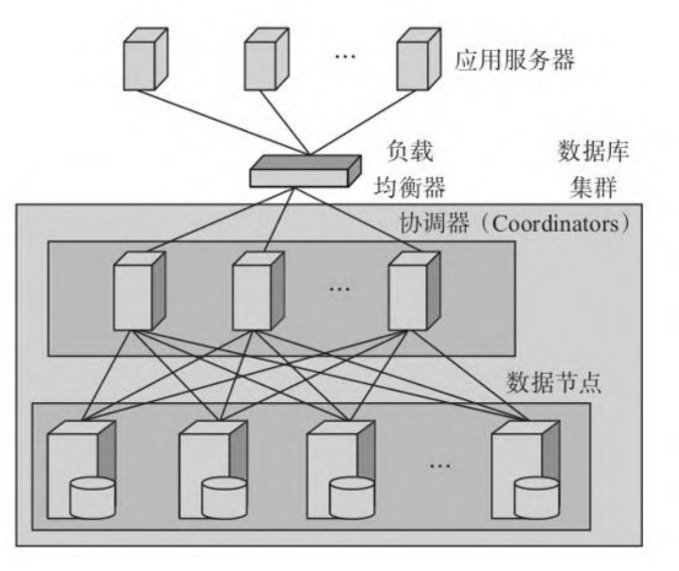
三、Postgres-XC的组件¶
Postgres-XC有以下不同角色的节点
-
Coordinators:本书中翻译为协调器。应用程序连接Postgres- XC,实际连接的就是Coordinators。它对 SQL进行分析,并生成全局的执行计划。为了节省机器,通常将此服务与数据节点部署在一起
-
Datanodes:数据节点,或简单地称之为“Nodes”,这是实际数据存储的节点,执行本地的SQL
-
全局事务管理器:管理全局的事务ID(GXID即Global Transaction ID)。PostgreSQL使用事务ID来控制 多版本,在Postgres-XC中由GTM提供统一的事务ID分配和管理。GTM控制着全局的多版本的可见性,也 提供一些全局值
四、Postgres-XC的安装¶
Postgres-XC项目托管在sourceforge网站上和github上,其网址为: http://sourceforge.net/projects/postgres-xc/
https://github.com/postgres-x2/postgres-x2
安装依赖
apt-get install zlib1g-dev libreadline6-dev bison flex libperl-dev python-dev
tar xvf pgxc-v1.1.tar.gz
./configure --prefix=/usr/local/pgxc1.1' '--with-perl' '- -with-python make
make install
五、配置Postgres-XC集群¶
集群规划列表: 规划列表中,有五台机器,2台用于部署gtm(全局事务管理)3台用于部署数据节点和协调器以及gtm proxy
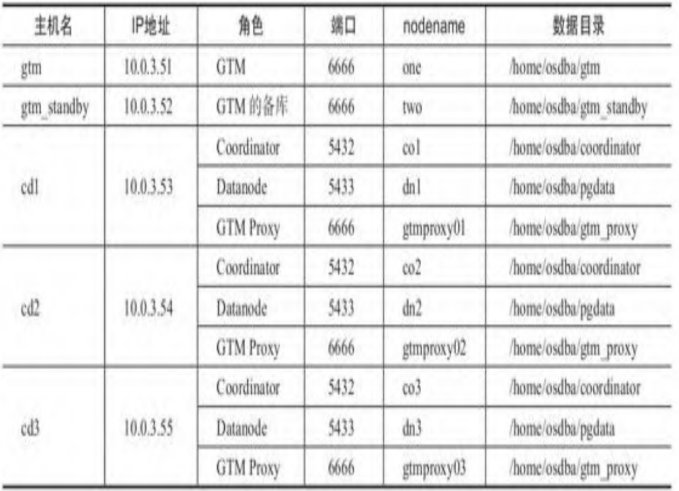
第一步:初始化GTM
/home/osdba/gtm/gtm.conf
nodename = 'one' listen_addresses = '*' port = 6666
startup = ACT
nodename:指定节点的名称,可指定为任意名称,不能与其他节点重名。
listen_addresses:GTM监听的IP地址,“*”表示在所有的IP地址上监听。
port:GTM监控的端口。
startup:GTM启动后是主库还是Standby,如果是主库,设置为“ACT”,如果是Standby,则设置为“STANDBY”
在gtm机器上执行 initgtm -Z gtm -D /home/osdba/gtm
初始gtm备库,备库配置
nodename = 'two'
listen_addresses = '*'
port = 6666
startup = STANDBY
active_host = 'gtm'
active_port = 6666
这里跟初始化主库一样 只需设置 nodename不要和主节点一样,startup设置为Standby 即可,active_host设置 为主节点的
第二步:初始化GTM Proxy
在每个部署数据的节点上执行如下 /home/osdba/gtm_proxy/gtm_proxy.conf”的内容如下
nodename = 'gtmproxy01'
port = 6666
gtm_host = 'gtm'
gtm_port = 6666
initgtm -Z gtm_proxy -D /home/osdba/gtm_proxy
其他节点配置初始化一样,只需要保证 nodename不要重复就好
第三步:初始化Coordinators、数据节点
在每个数据节点上进行初始化
的Coordinators的配置文件 /home/osdba/coordinator/postgres.conf
listen_addresses = '*'
port = 5432
logging_collector = on
gtm_host = 'gtm' # 填写gtm的地址
gtm_port = 6666
pgxc_node_name = 'coX' # 填写实际部署节点的名称每个节点不重复,比如co1,co2等
Datanodes的配置文 /home/osdba/pgdata/postgres.conf
listen_addresses = '*'
port = 5433
logging_collector = on
gtm_host = 'gtm'
gtm_port = 6666
pgxc_node_name = 'dnX' # 实际部署借的的名字不允许重复
进行每个节点初始
initdb --nodename coX -D /home/osdba/coordinator initdb --nodename dnX -D /home/osdba/pgdata
第四步:启动集群
启动集群的顺序如下
·GTM。
·GTM Standby。
·GTMProxy。
·Datanodes。
·Coordinators。
所以启动顺序如下: 在gtm主节点上启动
gtm_ctl -Z gtm start -D /home/osdba/gtm
在gtm备节点上启动
gtm_ctl -Z gtm_standby start -D /home/osdba/gtm_standby
在每个数据节点启动 启动gtm_proxy
gtm_ctl -Z gtm_proxy start -D /home/osdba/gtm_proxy
5.1 在每个数据节点上启动 node¶
pg_ctl start -D /home/osdba/pgdata -Z datanode
最后再 数据节点上启动 Coordinators
pg_ctl start -D /home/osdba/coordinator -Z coordinator
停止集群的顺序如下
·Coordinators。
·Datanodes。
·GTM Proxy。
·GTM。
·GTM Standby。
第五步:配置集群节点信息
启动集群后,还需要配置各个Coordinator中的集 群节点信息,然后集群才可以正常使用。配置方法是使用psql命令连接到各个Coordinator上,执行如下命令
create node co1 with (type = 'coordinator', host = 'cd1', port= 5432); create node co2 with (type = 'coordinator', host = 'cd2', port= 5432);
create node co3 with (type = 'coordinator', host = 'cd3', port= 5432); create node dn1 with (type = 'datanode', host = 'cd1', port = 5433);
create node dn2 with (type = 'datanode', host = 'cd2', port = 5433);
create node dn3 with (type = 'datanode', host = 'cd3', port = 5433);
六、Postgres-XC的使用¶
6.1 建表模式¶
根据数据的分布方式,Postgres-XC可以创建以下两种类型的表
-
Replicated tables:各个底层节点数据库上的表中的数据完全相 同。插入数据时,分别在各个底层节点数据库上插入相同的数据。读数据时,只需要读任意一个节点上的 数据创建表
-
Distributed tables:根据一个拆分规则把表的数据拆分到各个底 层的数据库数据节点上,也就是分布式数据库中常说的Sharding技术。 每个底层数据库节点上只保存表的一部分数据。
6.2 创建表案例¶
CREATE TABLE test05(id int primary key,id2 int UNIQUE, note text) DISTRIBUTE BY HASH(id) TO NODE (dn1, dn2, dn3);
6.3 使用限制¶
-
如果按“HASH”或“MODULO”创建表,则表上的唯一约束(包括主键约束)必须是分布键,如果不是分布 键,Postgres-XC无法在多个节点上保证数据的唯一性
-
分布键是不能更新的
-
统计信息并不是全局的,是由各个节点自己维护的
6.4 Postgres-XC的运维¶
6.5 比如分布式表,添加节点,删除节点等等¶
<PostgreSQL修炼之道:从小工到专家(第2版)> 这本书有详细的列出来了,大家用到的时候可以去查看