

一、Kafka 读写数据¶
参考文档
http://kafka.apache.org/quickstart 常见命令
kafka-topics.sh #消息的管理命令
kafka-console-producer.sh #生产者的模拟命令
kafka-console-consumer.sh #消费者的模拟命令
1.1 创建 Topic¶
创建topic名为 wang,partitions(分区)为3,replication(每个分区的副本数/每个分区的分区因子)为 2,包括leader和follower分区共2个
新版命令,通过--bootstrap-server指定kafka的地址
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --create --topic wang --bootstrap-server 10.0.0.101:9092 --partitions 3 --replication-factor 2
#在各节点上观察生成的相关数据
[root@node1 ~]#ls /usr/local/kafka/data/
[root@node2 ~]#ls /usr/local/kafka/data/
[root@node3 ~]#ls /usr/local/kafka/data/
#旧版命令,通过--zookeeper指定zookeeper的地址
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --create --zookeeper
10.0.0.101:2181, 10.0.0.102:2181, 10.0.0.103:2181 --partitions 3 --replication-factor 2 --topic wang
Created topic wang.
1.2 获取所有 Topic¶
新版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 10.0.0.101:9092
#旧版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --list --zookeeper
10.0.0.101:2181, 10.0.0.102:2181, 10.0.0.103:2181
wang
1.3 查看 Topic 详情¶
状态说明:wang 有三个分区分别为0、1、2,分区0的leader是3 (broker.id),分区 0 有2 个副本,并且状态都为 lsr(ln-sync,表示可以参加选举成为 leader)。
#新版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --describe --bootstrap-server 10.0.0.101:9092 --topic
wang
Topic: wang TopicId: beg6bPXwToW1yp7cuv7F8w PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: wang Partition: 0 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: wang Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: wang Partition: 2 Leader: 2 Replicas: 2,3 Isr: 2,3
#旧版命令
[root@node1 ~]#/usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper
10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 --topic wang
Topic: wang PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: wang Partition: 0 Leader: 3 Replicas: 3,2 Isr: 3,2
Topic: wang Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: wang Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1
1.4 生产 Topic¶
kafka-console-producer.sh 格式
#发送消息命令格式:
#新版
kafka-console-producer.sh --bootstrap-server <kafkaIP1>:<端口>,<kafkaIP2>:<端口> --topic <topic名称> --producerproperty group.id=<组名>
#旧版
kafka-console-producer.sh --broker-list <kafkaIP1>:<端口>,<kafkaIP2>:<端口> --topic <topic名称> --producerproperty group.id=<组名>
范例:
#交互式输入消息,按Ctrl+C退出
#新版
[root@node1 ~]#/usr/local/kafka/bin/kafka-console-producer.sh --bootstrap-server
10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic wang
#旧版
[root@node1 ~]#/usr/local/kafka/bin/kafka-console-producer.sh --broker-list
10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic wang
>message1
>message2
>message3
>
#或者下面方式
[root@node1 ~]#/usr/local/kafka/bin/kafka-console-producer.sh --topic wang --bootstrap-server 10.0.0.101:9092
1.5 消费 Topic¶
kafka-console-consumer.sh 格式
#接收消息命令格式:
kafka console -consumer.sh --bootstrap-server <host>::<post> --topic <topic名称> --from-beginning --consumer-property group.id=<组名称>
注意:
- 消息者先生产消息,消费者后续启动,默认不会收到之前生产的消息
- 添加选项 --from-beginning 表示消费前发布的消息也能收到,默认只能收到消费后发布的新消息
- 同一个消息在同一个group内的消费者只有被一个消费者消费,比如:共100条消息,在一个group内有A,B两个消费者,其中A消费50条,B消费另外的50条消息。从而实现负载均衡,不同group内的消费者则可以同时消费同一个消息
范例:
交互式持续接收消息,按Ctrl+C退出
#交互式持续接收消息,按Ctrl+C退出
[root@node1 ~]#/usr/local/kafka/bin/kafka-console-consumer.sh --topic wang --bootstrap-server 10.0.0.102:9092
--from-beginning
message1
message3
message2
#一个消息同时只能被同一个组内一个消费者消费(单播机制),实现负载均衡,而不能组可以同时消费同一个消息(多播机制)
[root@node2 ~]#/usr/local/kafka/bin/kafka-console-consumer.sh --topic wang --bootstrap-server 10.0.0.102:9092
--from-beginning --consumer-property group.id=group1
[root@node2 ~]#/usr/local/kafka/bin/kafka-console-consumer.sh --topic wang --bootstrap-server 10.0.0.102:9092
--from-beginning --consumer-property group.id=group1
1.6 删除 Topic¶
范例:
#注意:需要修改配置文件server.properties中的delete.topic.enable=true并重启
#新版本
[root@node3 ~]#/usr/local/kafka/bin/kafka-topics.sh --delete --bootstrap-server
10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092 --topic wang
#旧版本
[root@node3 ~]#/usr/local/kafka/bin/kafka-topics.sh --delete --zookeeper
10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 --topic wang
Topic wang is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
范例:删除zk下面 topic test
无需修改配置文件server.properties,此方法很危险
[root@zookeeper-node1 ~]#zkCli.sh -server 10.0.0.103:2181
[zk: 10.0.0.103:2181(CONNECTED) 0] ls /brokers/topics
[zk: 10.0.0.103:2181(CONNECTED) 0] deleteall /brokers/topics/test
[zk: 10.0.0.103:2181(CONNECTED) 0] ls /brokers/topics
1.7 消息积压¶
消息积压是指在消息传递系统中,积累了大量未被处理或未被消费的消息
Kafka 消息积压可能由多种原因引起,以下是一些可能的原因:
-
消费者处理速度慢: 如果消费者处理消息的速度不足以跟上生产者的速度,就会导致消息积压。这可能是因为消费者逻辑复杂、消费者数量不足,消费者岩机或者网终延迟等原因引起的
-
消费者宕机: 如果某个消费者宕机,其负责处理的分区将没有消费者来消费消息,导致消息在该分区上积压
-
网络问题: 网络故障可能导致生产者和消费者之间的通信延迟或中断,从而影响消息的传递速度
-
硬件资源不足: Kafka 集群所在的机器,包括生产者、消费者和 Broker 所在的机器,可能由于 CPU、内存或磁盘等资源不足,导致消息处理速度变慢
-
分区不均匀: 如果某些分区的负载比其他分区更高,可能导致这些分区上的消息积压。这可能是由于分区数量设置不合理、数据分布不均匀等原因引起的
-
生产者速度过快: 如果生产者生产消息的速度过快,而消费者无法及时处理,就会导致消息积压
-
配置不当: Kafka 的一些配置参数,如副本数、分区数、消费者数量等,需要根据实际情况进行合理的配置。如果配置不当,可能导致消息积压问题。
-
异常情况: 突发性的异常情况,如硬件故障、网络故障、软件 bug 等,都可能导致消息积压
Kafka 消息积压可能的解决方案:
-
增加消费者数量:如果消费者处理速度不足导致消息积压,可以增加消费者的数量来提高处理速度。
-
扩展Kafka集群:如果消息积压是由于Kafka集群的吞吐量达到极限导致的,考虑扩展Kafka集群的规模来增加其处理能力。
-
数据分区:合理划分数据分区可以提高并行处理能力,从而减少消息积压。
-
数据清理:定期清理过期的数据和日志文件,以释放磁盘空间并提高性能。
-
优化消费者代码:检查消费者代码,确保它们是高效的。可能存在一些性能瓶颈或不必要的延迟。
-
调整Kafka配置:根据需要调整Kafka的配置参数,例如增加分区数量、调整副本数量、调整日志清理策略等。
-
监控和警报:设置监控系统,及时发现消息积压问题并发送警报。这样可以在问题出现之前采取行动。
-
故障排除:检查系统日志,查找可能的问题源,并采取相应的措施解决问题。
kafka 要发现消息积压,可以考虑以下方法:
-
监控工具: Kafka 提供了一些监控工具,例如 Kafka Manager、Burrow、Kafka Offset Monitor 等。这些工具可以帮助你监控每个分区的偏移量(offset)和消费者组的状态。通过检查偏移量的增长速度,你可以判断是否有消息积压
-
Consumer Lag: Consumer Lag 是指消费者组相对于生产者的消息偏移量的差异。通过监控 Consumer Lag,你可以了解消费者是否跟上了生产者的速度。如果 Consumer Lag 增长较快,可能表示消息积压
-
Kafka Logs 目录: Kafka 的每个分区都有一个日志目录,其中包含了该分区的消息数据。可以检查每个分区的日志目录,查看是否有大量的未消费的消息
-
Kafka Broker Metrics: Kafka 提供了一系列的 broker metrics,包括消息入队速率、出队速率等。通过监控这些指标,可以了解Kafka 集群的负载状况
-
操作系统资源: 如果 Kafka 所在的机器资源不足,可能导致消息积压。监控 CPU、内存、磁盘等系统资源,确保它们没有达到极限
-
警报系统: 设置警报系统,当某些指标达到预定的阈值时触发警报,通知运维人员或相关团队及时处理
通过Kafka提供的工具查看格式:
发现当前消费的offset和最后一条的offset差距很大,说明有大量的数据积压
kafka-consumer-groups.sh --bootstrap-server {kafka连接地址} --describe --group {消费组} | --all-groups
范例:
模拟生产者生产大量消息
# 模拟生产者生产大量消息(无限自增数字)
[root@ubuntu2404 ~]# ( while true; do echo $i; let i++; done ) | /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 10.0.0.201:9092,10.0.0.202:9092,10.0.0.203:9092 --topic mytopic
# 查看所有消费组、所有主题的消息堆积(LAG=堆积数)
[root@ubuntu2404 ~]# /usr/local/kafka/bin/kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --all-groups
# 输出字段说明
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID
group1 wang 0 3 3 0 -
group1 test 0 4 11 7 -
二、Kafka 在 ZooKeeper 里面的存储结构¶
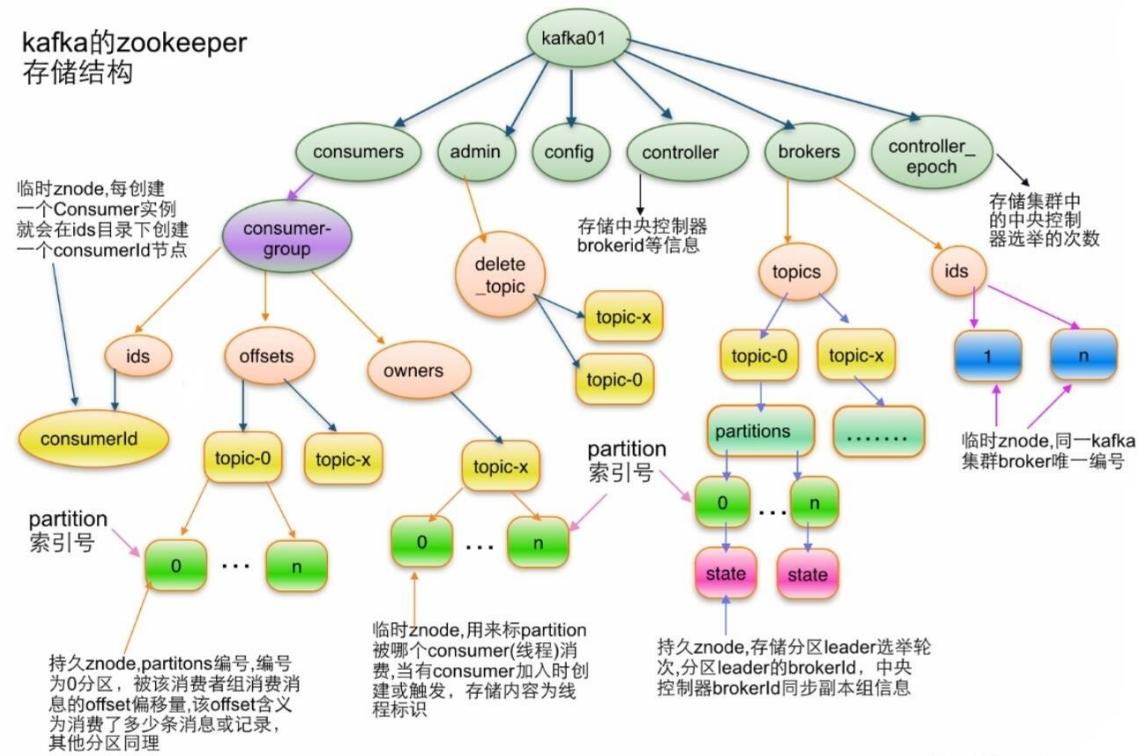
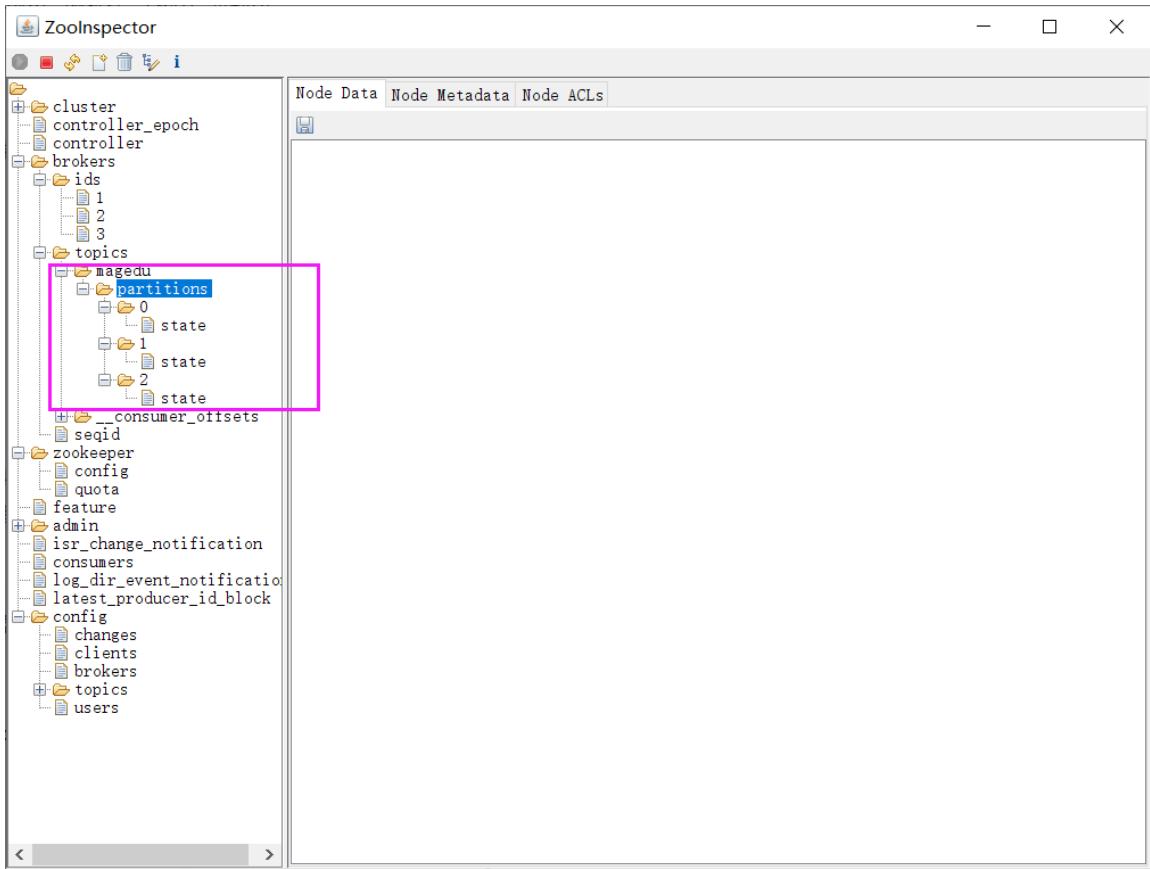
topic 结构
/brokerstopics/[topic]
partition结构
/brokers/topics/[topic]/partitions/[partitionId]/state
broker信息
/brokers/ids/[o...N]
控制器
/controller
存储center controller中央控制器所在kafka broker的信息
消费者
消费者信息:
/consumers/[groupId]/ids /[consumerIdstring]
每个consumer都有一个唯一的ID,此id用来标记消费者信息
消费者管理者:
/consumers/[groupId]/owners/[topic]/[partitionid]
三、Kafka 工具¶
3.1 图形工具 Offset Explorer (Kafka Tool)¶

Offset Explorer ,旧称Kafka Tool,工具是一个 GUI 应用程序,用于管理和使用 Apache Kafka 群集。它提供了一个直观的 UI,允许人们快速查看 Kafka 群集中的对象以及存储在群集主题中的消息。它包含面向开发人员和管理员的功能。一些关键功能包括
- 快速查看您的所有 Kafka 集群,包括其经纪人、主题和消费者
- 查看分区中邮件的内容并添加新邮件
- 查看消费者的偏移量,包括阿帕奇风暴卡夫卡喷口消费者
- 以漂亮的打印格式显示 JSON和 XML 消息
- 添加和删除主题以及其他管理功能
- 将单个邮件从分区保存到本地硬盘驱动器
- 编写自己的插件,允许您查看自定义数据格式
- Kafka 工具在Windows、Linux 和 Mac 操作系统上运行
官网:
https://www.kafkatool.com/
下载链接:
https://www.kafkatool.com/download.html



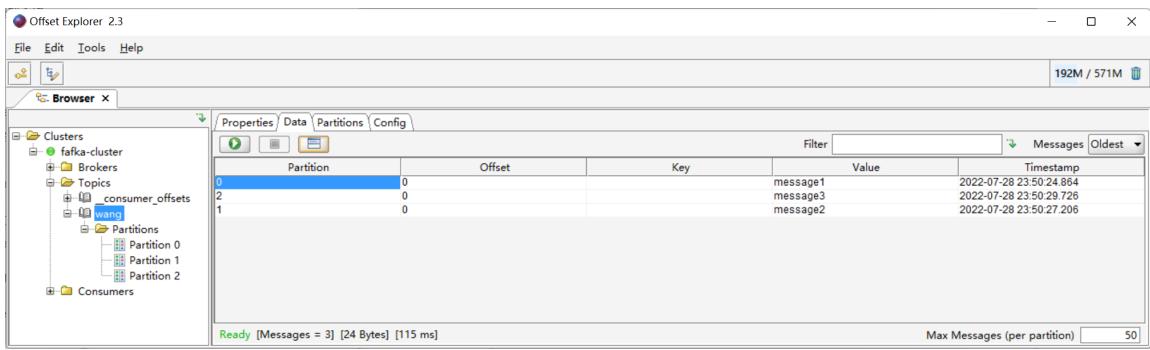
修改类型

查看数据
3.2 基于Web的Kafka集群监控系统 kafka-eagle¶
3.2.1 介绍¶
Kafka eagle(kafka鹰) 是一款由国内公司开源的Kafka集群监控系统,可以用来监视kafka集群的broker状态、Topic信息、IO、内存、consumer线程、偏移量等信息,并进行可视化图表展示。独特的KQL还可以通过SQL在线查询kafka中的数据。
官方地址
http://www.kafka-eagle.org/
https://github.com/smartloli/kafka-eagle-bin
https://www.cnblogs.com/smartloli/

3.2.2 安装¶
安装说明
https://docs.kafka-eagle.org/2.installation
https://www.cnblogs.com/smartloli/p/16728995.html
注意:当前最新版kafka-eagle-bin-3.0.2有bug,无法正常显示数据,可以选用kafka-eagle-bin-3.0.1版本
3.2.2.1 安装 JAVA¶
注意: 不支持JDK-11
apt update && apt -y install openjdk-8-jdk
3.2.2.2 下载安装¶
wget https://github.com/smartloli/kafka-eagle-bin/archive/refs-tags/v3.0.1.tar.gz
3.2.2.3 解压安装包¶
tar zxf kafka-eagle-bin-3.0.1.tar.gz
cd kafka-eagle-bin-3.0.1/
tar -zxvf kafka-eagle-web-3.0.1-bin.tar.gz -C /usr/local/
ln -s /usr/local/efak-web-3.0.1 /usr/local/kafka-eagle-web
3.2.2.4 设置全局变量¶
设置相关全局变量KE_HOME
vi /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export KE_HOME=/usr/local/kafka-eagle-web
export PATH=$PATH:$KE_HOME/bin
./etc/profile
3.2.2.5 修改配置文件¶
######################################
# 填写 zookeeper集群列表
# kafka 节点配置属性,多个集群用逗号分隔
efak.zk.cluster.alias=cluster1
######################################
######################################
# zookeeper地址(修改为你的ZK集群)
######################################
cluster1.zk.list=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
######################################
# broker 最大规模数量
######################################
cluster1.efak.broker.size=20
######################################
# zk 客户端线程数
######################################
kafka.zk.limit.size=32
######################################
# EFAK webui 端口
######################################
efak.webui.port=8048
######################################
# kafka offset storage
######################################
cluster1.efak.offset.storage=kafka
######################################
# kafka jmx uri
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka metrics 指标,默认存储15天
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql topic records max
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# delete kafka topic token
######################################
efak.topic.token=keadmin
######################################
# kafka sqlite 数据库(默认使用)
######################################
efak.driver=org.sqlite.JDBC
efak.url=jdbc:sqlite:/usr/local/kafka-eagle-web/db/ke.db
efak.username=root
efak.password=www.kafka-eagle.org
######################################
# mysql 数据库(注释掉,不使用)
######################################
#efak.driver=com.mysql.cj.jdbc.Driver
#efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
#efak.username=ke
#efak.password=123456
3.2.2.6 启动¶
# 内存优化(修改 ke.sh 启动脚本)
[root@ubuntu2404 ~]# vim /usr/local/kafka-eagle-web/bin/ke.sh
# 找到 JAVA_OPTS 并替换为以下配置(完整一行,无换行)
export KE_JAVA_OPTS="-server -Xmx2g -Xms2g -XX:MaxGCPauseMillis=20 -XX:+UseG1GC -XX:MetaspaceSize=128m -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80"
# 启动 Kafka-Eagle
[root@ubuntu2404 ~]# /usr/local/kafka-eagle-web/bin/ke.sh start
# 实时查看运行日志(观察是否正常启动)
[root@ubuntu2404 ~]# tail -f /usr/local/kafka-eagle-web/logs/*
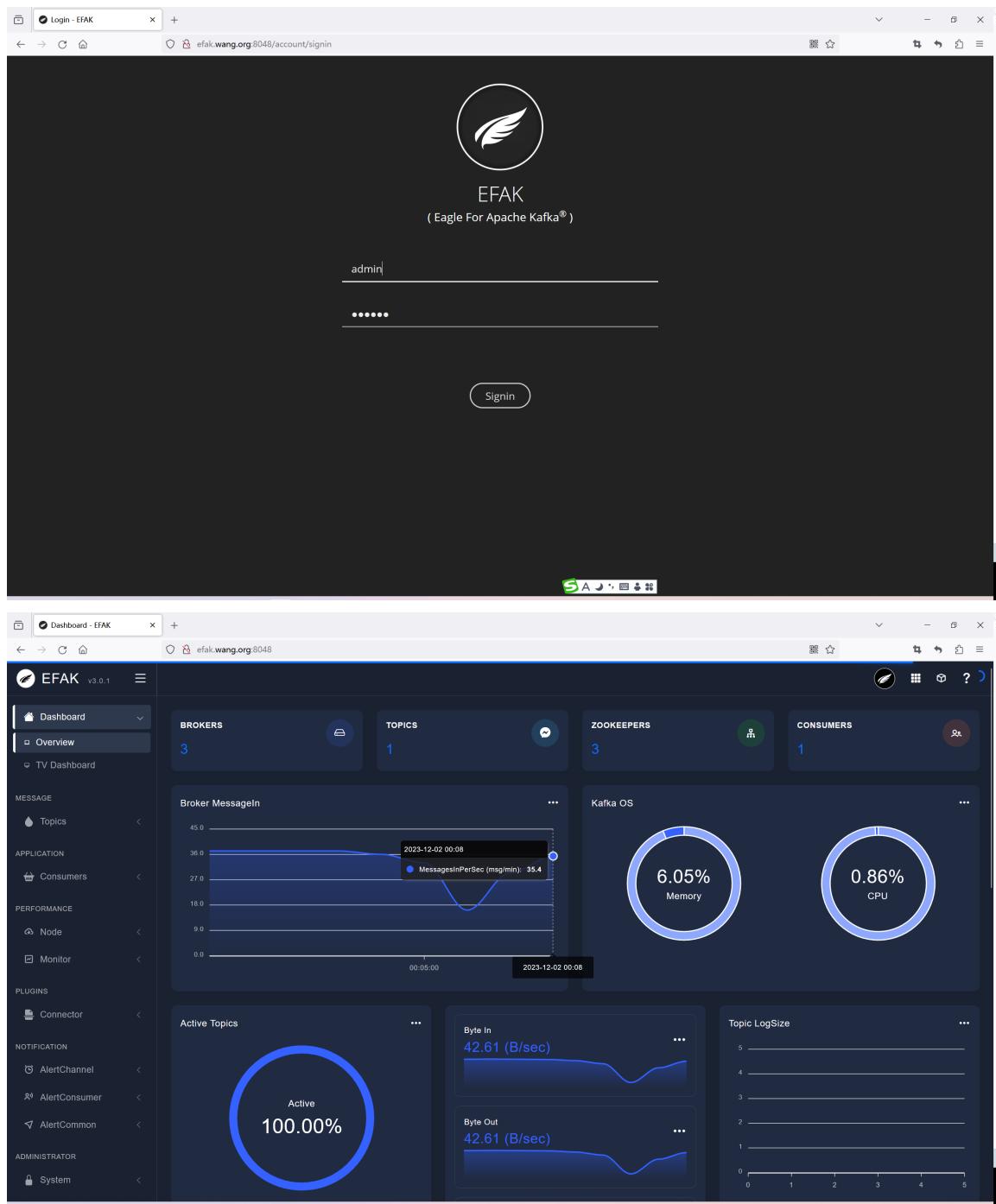
3.2.2.7 登录¶
http://localhost:8048 默认账号:admin
默认密码:123456

默认 kafka 没有开启JMX,无法监控到Kafka的相关数据

3.2.2.8 修改和监控 Kafka¶
所有kafka节点修改配置
[root@node1 ~]#vim /usr/local/kafka/bin/kafka-server-start.sh
......
if[ " x$KAFKA_HEAP_OPTIONS"="x" ]; then
export KAFKA_HEAP_OPTIONS=" -xmx1G-Xms1G"
export JMX_PORT="9999" #添加此行
fi
......
[root@node1 ~]#systemctl restart kafka
#将Kafka-eagle重启
[root@ubuntu2404 ~]#/usr/local/kafka-eagle-web/bin/ke.sh resta
3.2.2.9 通过 Kafka-eagle 监控¶
测试访问
[root@ubuntu2404 ~]#while true;do let i++; echo $i | /usr/local/kafta/bin/kafta console-producer.sh --broker-list 10.0.0.101:9092 --topic wangtopic ;done
注意:kafka-eagle-bin-3.0.2有bug,选择kafka-eagle-bin-3.0.1版本才能看到数据展示
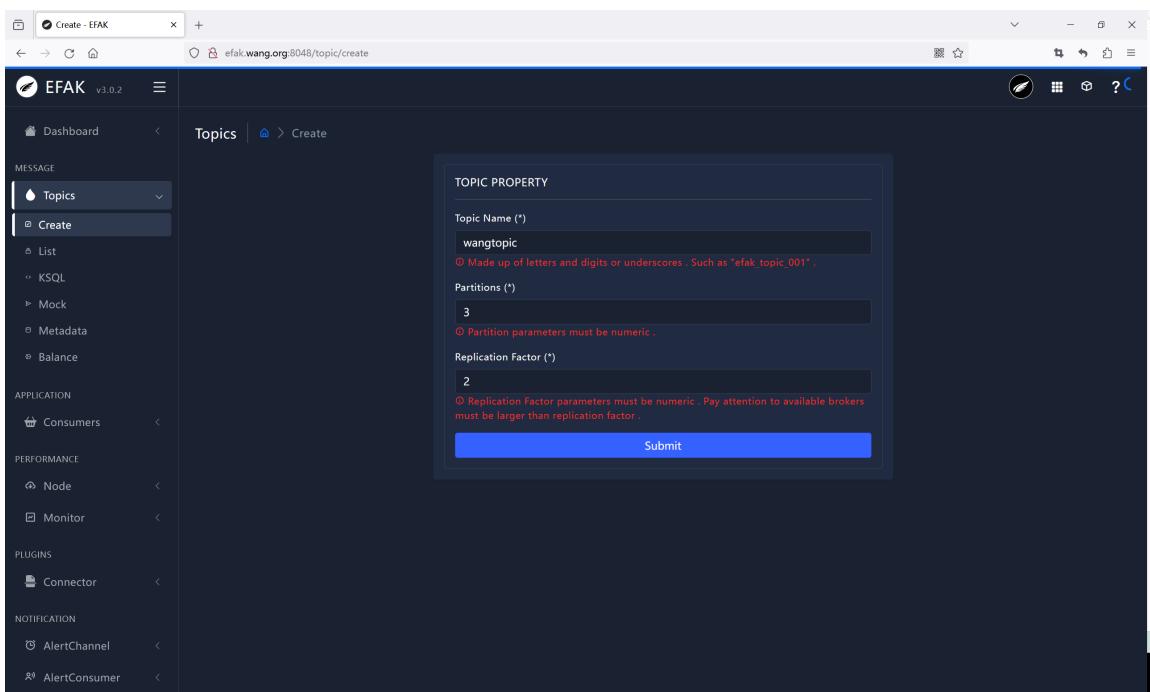
创建topic
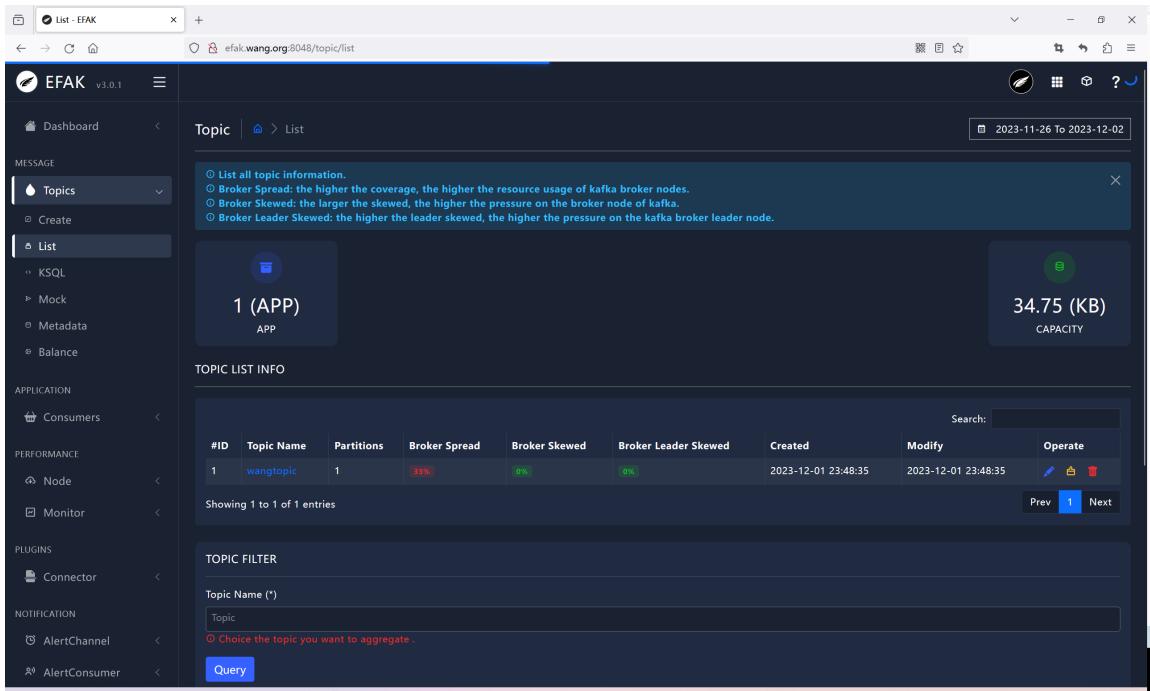
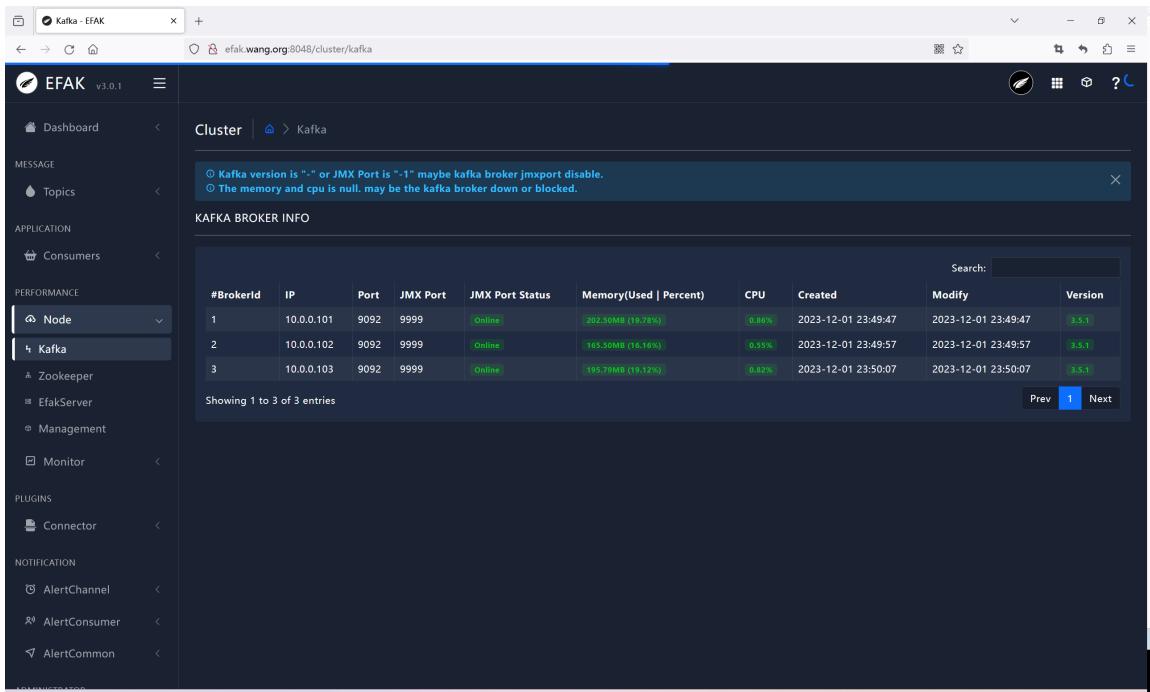
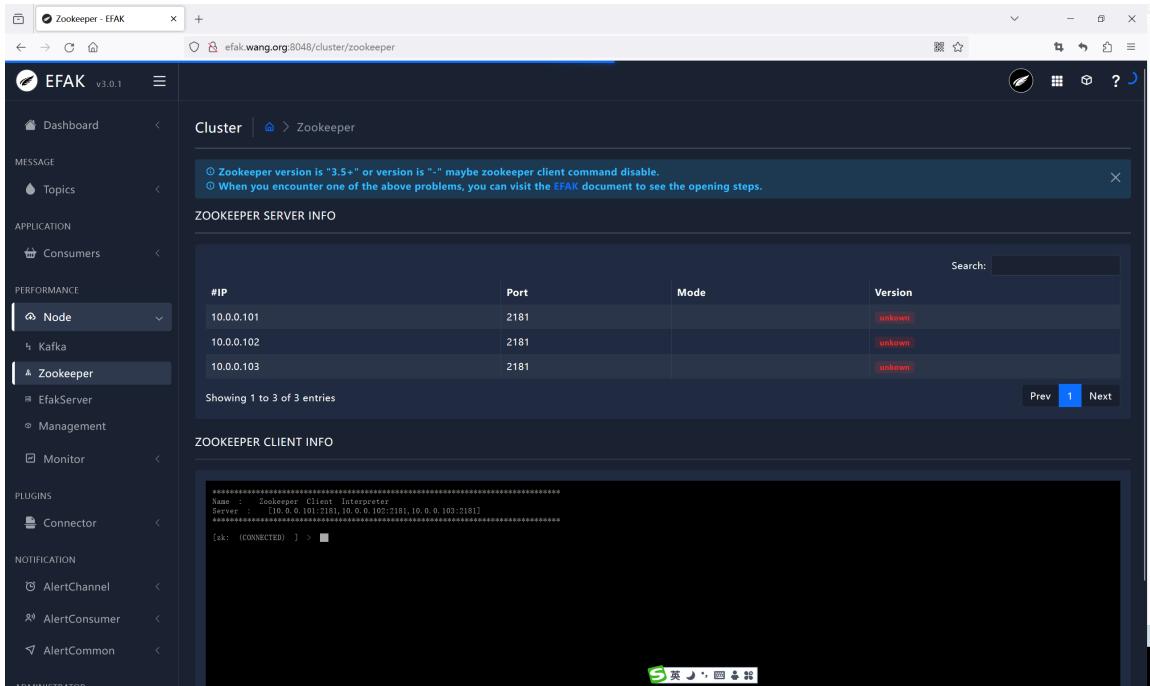
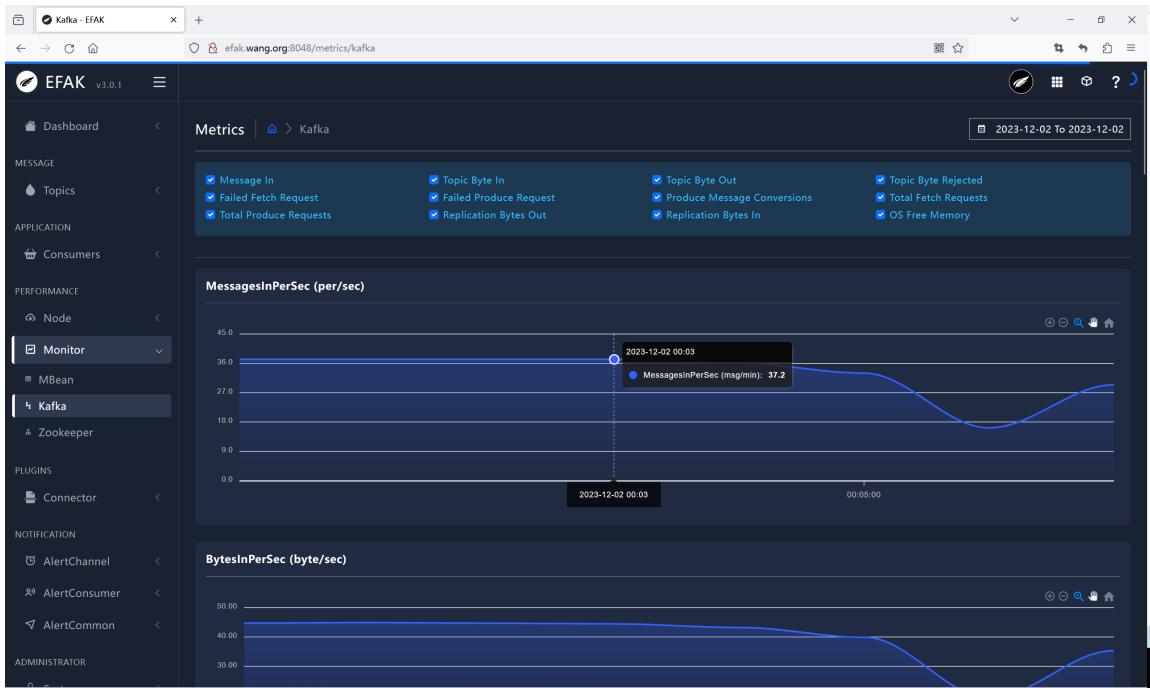
多次访问后可以看到如下

3.3 kafka-UI¶
https://docs.kafka-ui.provectus.io/ https://github.com/provectus/kafka-ui https://hub.docker.com/r/provectuslabs/kafka-ui/ Apache Kafka 的 UI 是一种多功能、快速且轻量级的 Web UI,用于管理 Apache Kafka® 集群。由开发人员构建,为开发人员服务。
该应用程序是一个免费的开源 Web UI,用于监控和管理 Apache Kafka 集群。
适用于 Apache Kafka 的 UI 是一个简单的工具,可让您的数据流可观察,有助于更快地发现和排查问题,并提供最佳性能。其轻量级控制面板可以轻松跟踪 Kafka 集群的关键指标: Brokers, Topics, Partitions、生产和消费。
范例:容器化部署
[root@ubuntu2404 ~]#docker run --name kafka-ui -it -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true
provectuslabs/kafka-ui
[root@ubuntu2404 ~]#docker run --name kafka-ui -it -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true registry.cn-beijing.aliyuncs.com/zhangqing/kafka-ui:v0.7.2
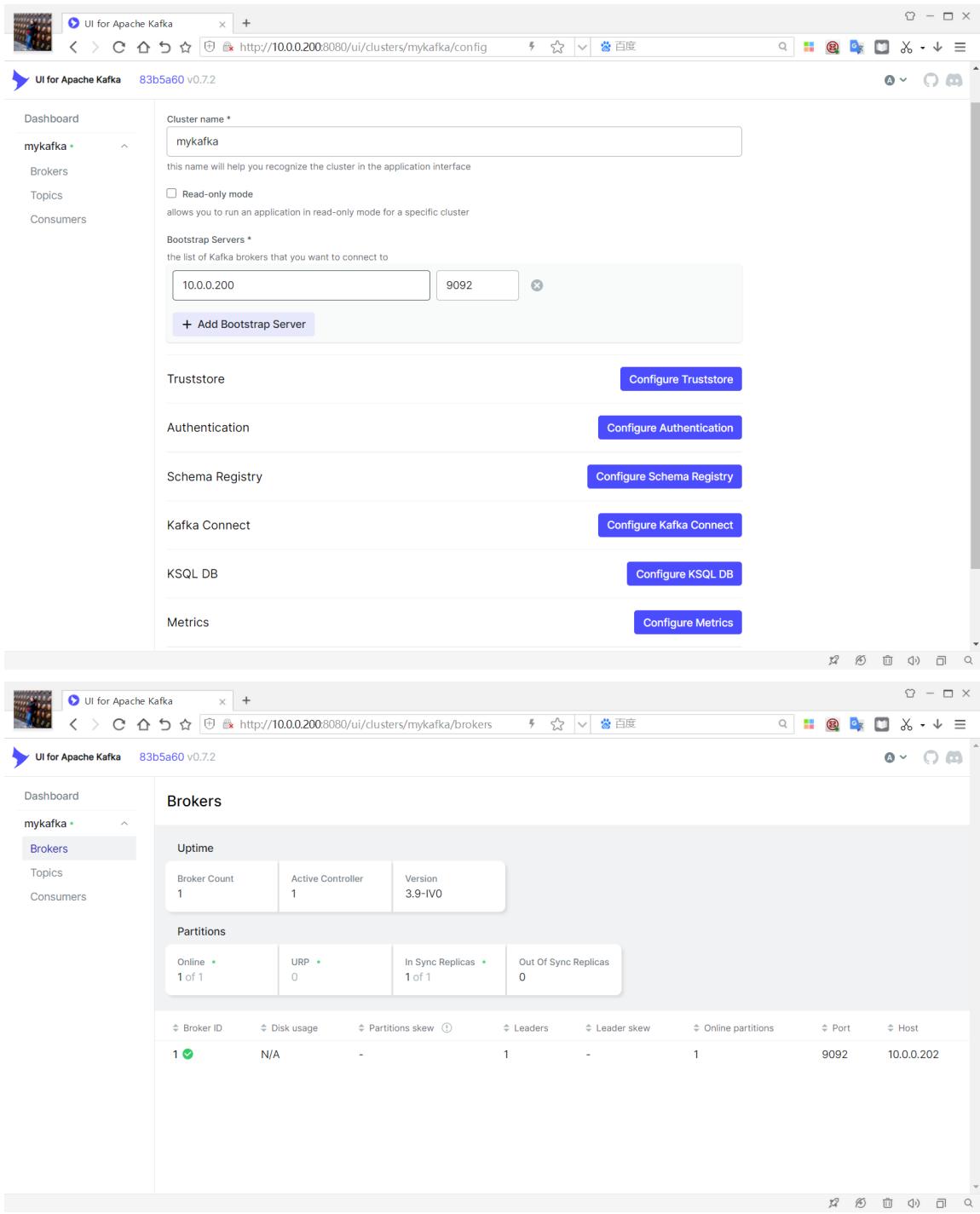
范例: docker-compose部署
https://docs.kafka-ui.provectus.io/configuration/configuration-file
# https://docs.kafka-ui.provectus.io/configuration/configuration-file
version: '3'
services:
kafka-ui:
container_name: kafka-ui
image: registry.cn-beijing.aliyuncs.com/zhangqing/kafka-ui:v0.7.2
ports:
- 8080:8080
depends_on:
- kafka0
environment:
DYNAMIC_CONFIG_ENABLED: 'true'
KAFKA_CLUSTERS_0_NAME: wizard_test
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka0:29092
3.4 Kafka Manager¶
https://github.com/yahoo/CMAK
CMAK 原名 kafka manager 是一个yahoo 公司开源的 kafka 管理工具
因 Apache 版权,后来从“kafka manager”改名为“CMAK”,意为“Cluster Manager for Apache Kafka”。
Kafka Manager是用于管理Apache Kafka 集群的工具。为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。
这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,有如下功能:
1.管理多个kafka集群
2.便捷的检查kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
3.选择你要运行的副本
4.基于当前分区状况进行
5.可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
6.删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
7.Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
8.为已存在的topic增加分区
9.为已存在的topic更新配置
10.在多个topic上批量重分区
11.在多个topic上批量重分区(可选partition broker位置)
下载
https://github.com/yahoo/CMAK/releases https://blog.wolfgre.com/posts/kafka-manager-download/
四、Kafka 监控¶
Prometheus 监控 kafka
https://github.com/danielqsj/kafka_exporter

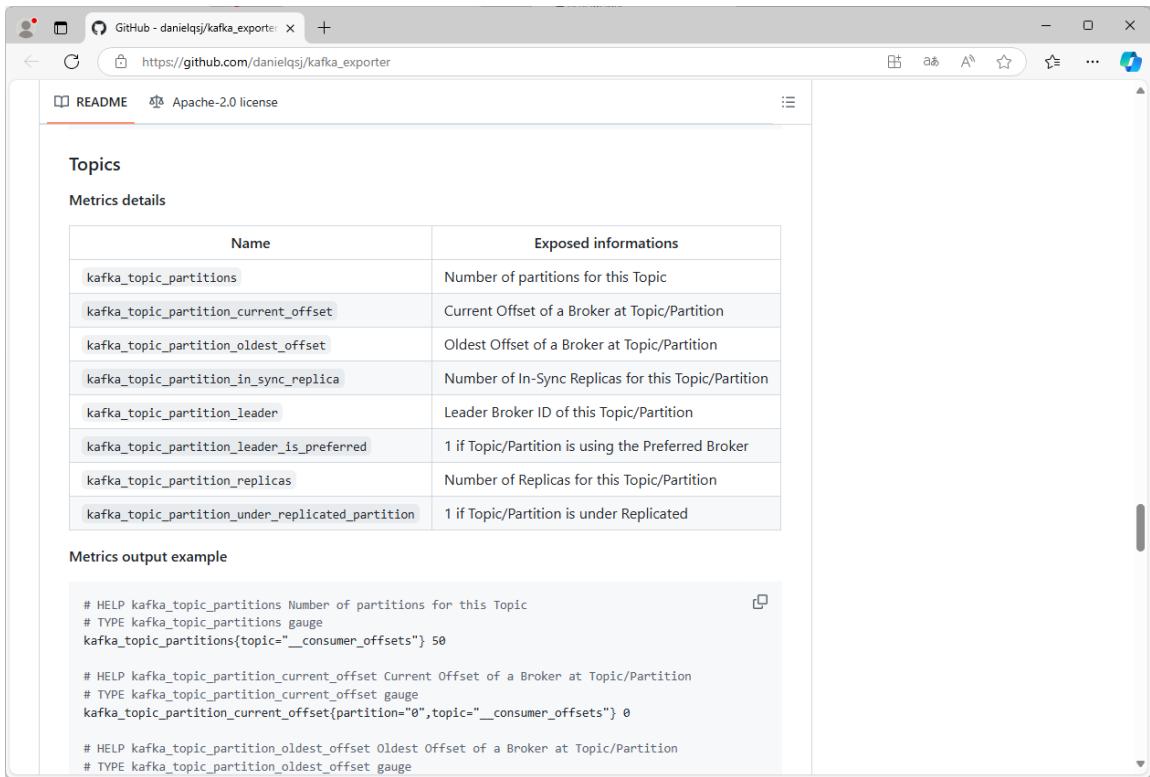
Kafka 常用监控指标
Kafka集群
| 序号 | 指标别名 | 指标含义解释 | 单位 |
|---|---|---|---|
| 1 | Partitions总数 | 集群中所有节点Partition数之和 | 个 |
| 2 | 未复制分区总数 | 集群中所有节点未复制分区数之和 | 个 |
| 3 | 离线分区总数 | 集群中所有节点离线分区数之和 | 个 |
| 4 | Controller存活数 | 集群中Controller存活的数量 | 个 |
| 5 | 失败请求(生产者) | 集群中所有节点生产者失败请求的速率之和 | 次/s |
| 6 | 失败请求(消费者) | 集群中所有节点消费者失败请求的速率 | 次/s |
| 7 | 生产者流量 | 集群中所有节点生产者流量之和 | Bytes/s |
| 8 | 消费者流量 | 集群中所有节点消费者流量之和 | Bytes/s |
| 9 | 生产者QPS | 集群中所有节点生产者QPS之和 | 次/s |
| 10 | 消费者QPS | 集群中所有节点消费者QPS之和 | 次/s |
| 11 | 存活节点数 | 集群中存活的节点数量 | 个 |
| 12 | 每秒流入消息数 | 集群中所有节点流入消息数之和 | 个/s |
| 13 | 最大CPU利用率 | 集群中所有节点CPU利用率最大值 | |
| 14 | 最大内存利用率 | 集群中所有节点内存利用率最大值 | |
| 15 | 最大Heap区利用率 | 集群中所有节点堆内存利用率最大值 | |
| 16 | 最大Non-Heap区利用率 | 集群中所有节点非堆内存利用率最大值 | |
| 17 | 最大Minor GC次数 | 集群中所有节点每分钟Minor GC次数最大值 | |
| 18 | 最大Major GC次数 | 集群中所有节点每分钟Major GC次数最大值 | |
| 19 | 最大Minor GC时间 | 集群中所有节点每分钟Minor GC时间 | |
| 20 | 最大Major GC时间 | 集群中所有节点每分钟Major GC时间 |
Broker指标
| 序号 | 指标别名 | 指标含义解释 | 单位 |
|---|---|---|---|
| 1 | CPU利用率 | % | |
| 2 | 内存利用率 | % | |
| 3 | 内存使用量 | Bytes | |
| 4 | 磁盘吞吐(Read) | Bytes/s | |
| 5 | 磁盘吞吐(Write) | Bytes/s | |
| 6 | 生产者流量 | Bytes | |
| 7 | 消费者流量 | Bytes | |
| 8 | 生产者QPS | ||
| 9 | 消费者QPS | ||
| 10 | 是否是Controller | 0:不是,1:是 | |
| 11 | Follower落后Leader最大消息量 | 个 | |
| 12 | Partition总数 | 该节点分区总数 | 个 |
| 13 | Leader分区总数 | 个 | |
| 14 | 未复制分区总数 | 个 | |
| 15 | ISR扩大速率 | 个/s | |
| 16 | ISR收缩速率 | 个/s | |
| 17 | 离线分区总数 | 个 | |
| 18 | Broker拒绝的消息 | Byte/s | |
| 19 | 生产者失败请求 | 次/s | |
| 20 | 消费者失败请求 | 次/s | |
| 21 | 生产者请求响应时间分位值 | request="Produce" | ms |
| 22 | 消费者请求响应时间分位值 | request="FetchConsumer" | ms |
| 23 | fetch请求速率 | ||
| 24 | 失败的fetch请求数 | ||
| 25 | zookeeper 连接断开速率 | 客户端已断开与服务器的连接,并尝试重新连接。会话不一定过期。 | |
| 26 | zookeeper 会话过期速率 | ||
| 27 | broker请求zk响应时间分位值 |
Topic指标
| 序号 | 指标别名 | 指标含义解释 | 单位 |
|---|---|---|---|
| 1 | 生产者流量 | ||
| 2 | 消费者流量 | ||
| 3 | 生产者QPS | ||
| 4 | 消费者QPS | ||
| 5 | Topic大小 |
ConsumerGroup指标
| 序号 | 指标别名 | 指标含义解释 | 单位 |
|---|---|---|---|
| 1 | 生产者QPS | ||
| 2 | 消费者QPS | ||
| 3 | Current-Offset | ||
| 4 | Log-End-Offset | ||
| 5 | Lag | 消息积压 | |
| 6 | 消费组状态 |