
一、为什么使用k8s管理GPU与大模型¶
我们可以从下面六个角度进行分析为什么使用k8s管理GPU与大模型:
-
资源调度与优化
-
多租户隔离与资源分配
-
简化部署与管理
-
弹性伸缩和负载均衡
-
高可用性与故障恢复
-
生态集成与工具链支持
1.1 资源调度与优化¶
- 精细化资源分配: Kubernetes 支持通过 Device Plugin(如 NVIDIA GPU 插件)识别 GPU 资源,结合调度策略(如 Volcano 批处理调度器)实现显存、算力的细粒度分配。例如,可以将单块 GPU 的显存或算力分割给多个任务(如 MIG 技术),避免资源浪费。
- 资源超卖与优先级: 针对大模型训练和推理的混合场景,K8s 可根据任务优先级动态调整 GPU 资源分配,例如优先保证在线推理服务的 SLA,同时利用空闲资源运行低优先级训练任务。
- 自动扩缩容: 结合 Cluster Autoscaler 和自定义指标(如 GPU 利用率、显存占用率),自动扩展 GPU 节点或调整 Pod 副本数,应对突发负载或节省成本。
1.2 多租户隔离与资源分配¶
- 命名空间隔离: 通过 Kubernetes Namespace 实现多租户逻辑隔离,结合 ResourceQuota 限制每个团队的 GPU 资源配额,防止资源滥用。
- 硬件级隔离: 利用节点标签(NodeSelector)或 GPU 设备插件,将特定 GPU 卡或节点绑定到特定租户,避免跨租户资源争用。
- 服务质量(QoS): 通过 QoS 策略(Guaranteed/Burstable)确保关键任务(如实时推理)的 GPU 资源不被抢占,同时允许弹性任务(如离线训练)共享剩余资源。
1.3 简化部署与管理¶
- 声明式配置: 使用 YAML 或 Helm Chart 定义大模型训练/推理任务的依赖(如 CUDA 版本、模型文件、数据集),实现一键部署和版本化管理。
- 容器化环境: 将复杂的 AI 框架(如 PyTorch、TensorFlow)、CUDA 驱动、模型代码封装为容器镜像,屏蔽环境差异,确保跨节点一致性。
- Operator 模式: 通过自定义 Operator(如 Kubeflow TFJob/PyTorchJob)自动化管理大模型任务的生命周期,例如自动重试失败任务、保存训练中间状态。
1.4 弹性伸缩和负载均衡¶
- 横向扩展(HPA): 针对大模型推理服务,基于请求量或 GPU 利用率自动增减 Pod 副本数。例如,使用 K8s HPA 结合 Prometheus 监控指标,实现动态扩缩容。
- 推理服务负载均衡: 通过 Service 和 Ingress 将请求分发到多个推理 Pod,避免单点瓶颈。结合模型分片(如 Triton Inference Server)优化 GPU 利用率。
- 预热与冷启动优化: 针对 GPU 模型加载时间长的场景,使用 K8s Readiness Probe 和 Pod 预热机制,减少冷启动对服务质量的影响。
1.5 高可用性与故障恢复¶
- 容错与自愈: K8s 自动监控 Pod 状态,当 GPU 节点故障或任务崩溃时,自动重启 Pod 或迁移到健康节点。结合 Checkpointing 技术(如 PyTorch Lightning),恢复中断的大模型训练任务。
- 持久化存储: 通过 PVC/PV 将训练数据、模型权重存储在分布式存储(如 Ceph、NFS)中,避免节点故障导致数据丢失。
- 跨可用区部署: 在多个可用区(AZ)部署 GPU 节点,结合 Pod 反亲和性策略,提升大模型服务的容灾能力。
1.6 生态集成与工具链支持¶
- AI/ML 工具链整合: Kubernetes 与主流 AI 生态无缝集成,例如:
- Kubeflow:管理机器学习流水线(Pipeline)、超参数调优(Katib)。
- Prometheus+Grafana:监控 GPU 显存、算力、温度等指标。
- NVIDIA DGX 系统:通过 GPU Operator 自动管理驱动和插件。
- 自定义调度器: 支持 Volcano、Kube-batch 等调度器优化大模型任务的资源抢占策略(如 Gang Scheduling),避免分布式训练因资源不足而停滞。
- Serverless 化: 结合 K8s 的虚拟化层(如 KubeVirt)或 Serverless 框架(如 Knative),实现按需启动 GPU 实例,进一步降低成本。
1.7 总结¶
Kubernetes 在管理 GPU 和大模型时,通过资源调度优化、多租户隔离和自动化运维,显著提升硬件利用率和管理效率,同时借助弹性伸缩和高可用架构保障服务的稳定性。其丰富的生态工具链(如 Kubeflow、Prometheus)和社区支持,进一步降低了 AI 基础设施的复杂度,使其成为大规模 GPU 集群和 AI 工作负载的工业级解决方案。
- AI/ML 工具链整合: Kubernetes 与主流 AI 生态无缝集成,例如:
- Kubeflow:管理机器学习流水线(Pipeline)、超参数调优(Katib)。
- Prometheus+Grafana:监控 GPU 显存、算力、温度等指标。
- NVIDIA DGX 系统:通过 GPU Operator 自动管理驱动和插件。
- 自定义调度器: 支持 Volcano、Kube-batch 等调度器优化大模型任务的资源抢占策略(如 Gang Scheduling),避免分布式训练因资源不足而停滞。
- Serverless 化: 结合 K8s 的虚拟化层(如 KubeVirt)或 Serverless 框架(如 Knative),实现按需启动 GPU 实例,进一步降低成本。
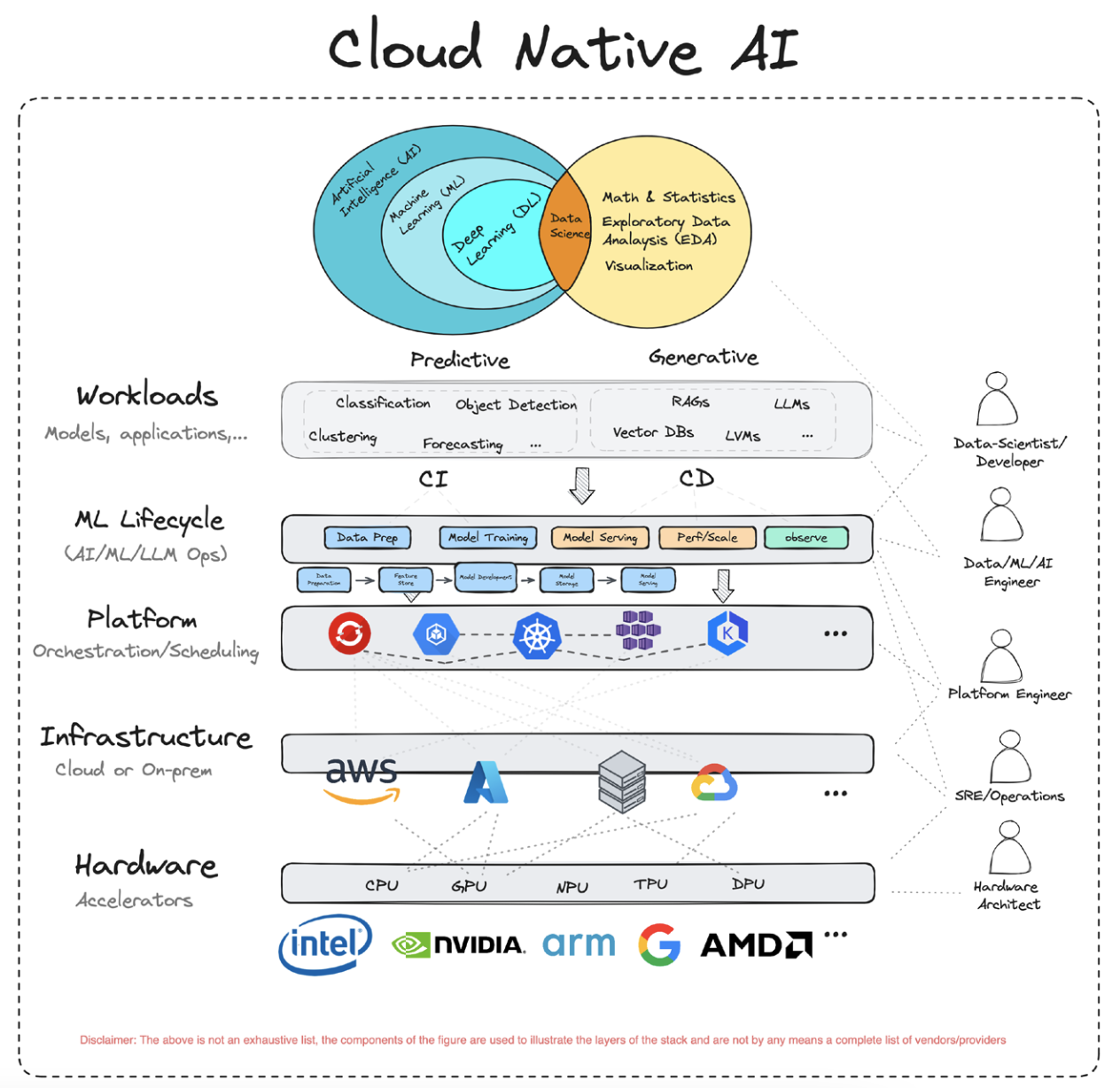
二、云原生人工智能(CNAI)¶
2.1 CNAI介绍¶
云原生人工智能(CNA)是指使用云原生技术构建和部署人工智能应用和工作负载。其核心是将A与云原生技术(如容器化、微服务、DevOpss等)相结合,以实现更高效、更灵活、更可靠的A应用开发和部署。
