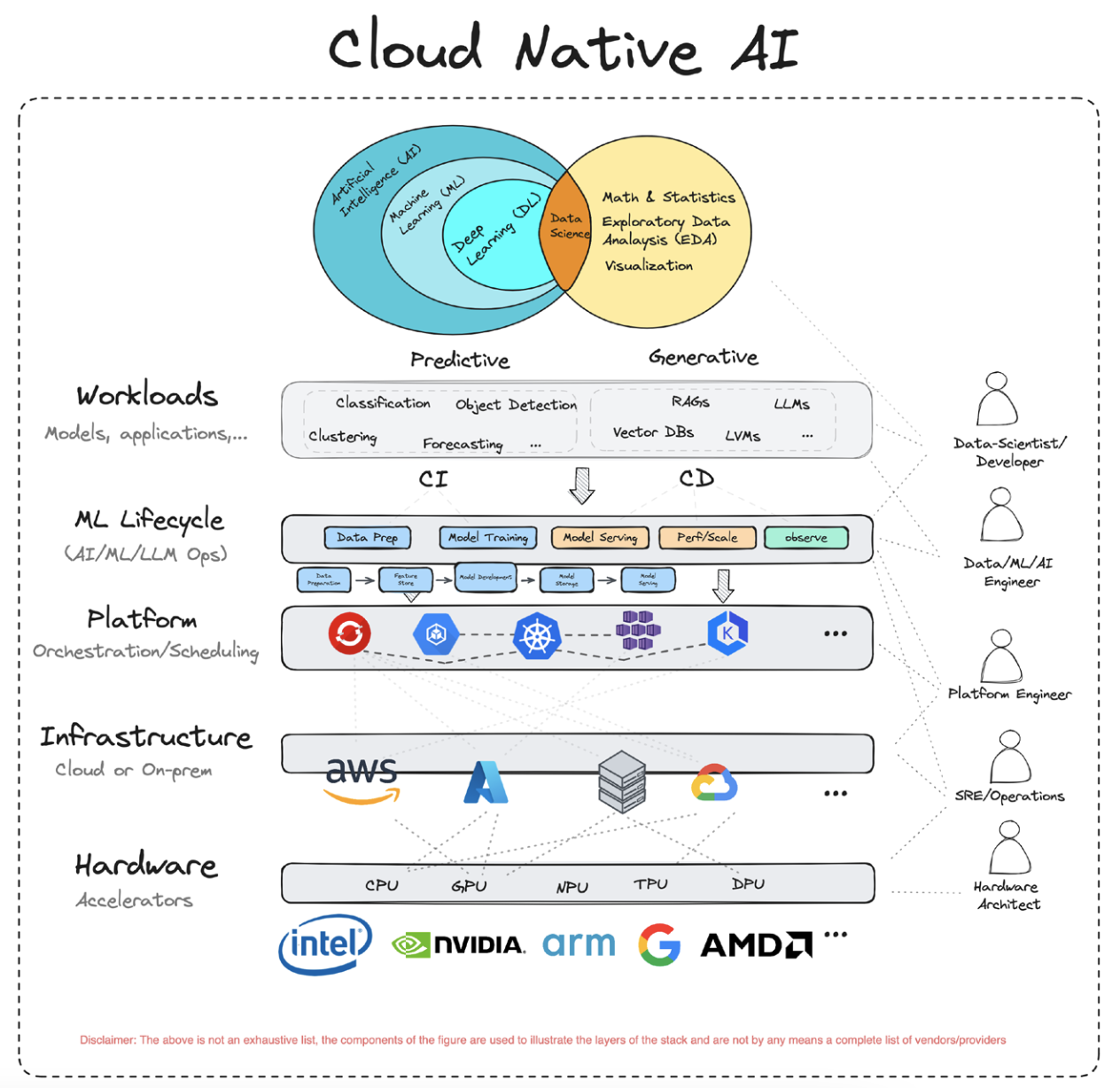

一、K8s管理GPU资源技术架构¶
k8s默认不支持管理GPU
Capacity:
cpu: "16"
ephemeral-storage: "524027908Ki"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: "65333844Ki"
pods: "110"
安装完英伟达驱动后支持管理GPU
Capacity:
cpu: "240"
ephemeral-storage: "1967569888Ki"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: "131470132Ki"
nvidia.com/gpu: "4"
pods: "110"
二、K8s管理大模型服务方案¶
针对vLLM serve、Ollama serve等各类大模型服务,可以使用资源类型为Deployment进行管理
三、K8s GPU Operator介绍¶
Kubernetes GPU Operator由英伟达开发,利用Kubernetest中的Operator框架,自动化管理所有用于配置GPU所需的NVIDIA软件,比t如NVIDIA Driver Manager、NVIDIA Container Toolkit、NVIDIA Device Plugin、NVIDIA DCGM等。

- NVIDIA Driver Manager:负责安装和管理Kubernetes节点上所需的NVIDIA驱动程序,确保GPU能够被容器和宿主机识别
- NVIDIA Container Toolkit:提供了对运行时GPU配置的支持,得容器内的应用程序能够访问主机上的NVIDIA GPU和相关库
- NVIDIA Device Plugin:负责上报GPU资源状态,让Kubernetes可以调度和管理GPU资源
- NVIDIA DCGM:全称Data Center GPU Manager,主要用于采集GPU的性能指标,比如温度、利用率等,同时提供API可以与其他工具集成
四、K8s Ollama Operator介绍¶
Kubernetes Ollama Operator同样使用Kubernetes Operator框架实现,主要用于将Ollama-与Kubernetes调度能力结合在一起,实现在Kubernetes中轻松管理、配置和维护大模型。
Ollama Operator提供名为Model的自定义资源,可以像管理Kubernetes核心资源一样管理模型服务。同时也提供了一个名为Kollama的客户端工具,可以像Kubect1一样管理模型服务。
五、K8s Ollama Operator核心资源介绍¶
5.1 Model¶
5.1.1 Model资源定义¶
Model 资源是 Ollama Operator 的核心组件,用于描述和配置一个大型语言模型的部署。它通过 YAML 文件定义,包含模型的名称、镜像、存储、资源限制等信息。以下是一个典型的 Model 资源示例:
apiVersion: ollama.ayaka.io/v1
kind: Model
metadata:
name: phi
namespace: ollama-llms
spec:
image: phi
storageClassName: local-path
replicas: 1
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 1
requests:
cpu: "2"
memory: "8Gi"
5.1.2 Model资源关键字段¶
metadata
- name: 模型的名称,用于唯一标识该模型实例。
- namespace: 模型所属的命名空间,用于资源隔离和管理。
spec
- image: 指定模型的镜像名称,例如
phi或llama3。镜像可以从 Ollama 的模型库中拉取,也可以通过自定义 Modelfile 创建。 - storageClassName: 指定存储类名称,用于管理模型的持久化存储。例如,
local-path表示使用本地存储。 - replicas: 模型的副本数,用于控制模型的并发处理能力。
- imagePullPolicy: 镜像拉取策略,例如
IfNotPresent表示如果本地已存在镜像则不重新拉取。 - resources: 定义模型的资源限制和请求,包括 CPU、内存和 GPU 资源。例如,
nvidia.com/gpu: 1表示分配一个 GPU 资源。
5.1.3 Model资源功能¶
1、模型部署
通过 Model 资源,用户可以轻松部署大型语言模型。Ollama Operator 会根据 YAML 文件中的配置自动拉取镜像、分配资源并启动模型服务
2、模型管理
- 模型更新: 修改 Model 资源的配置(如镜像版本或资源限制)后,Ollama Operator 会自动更新模型实例。
- 模型删除: 删除 Model 资源后,相关的模型实例和资源会被清理
3、资源优化
通过 resources 字段,用户可以精确控制模型的资源使用情况,例如限制 GPU 使用量或分配更多内存,以提高模型的运行效率
5.1.4 Model资源的应用场景¶
1、本地推理
Model 资源支持在本地环境中运行大型语言模型,适用于需要数据隐私或低延迟的场景
2、多模型管理
通过定义多个 Model 资源,用户可以同时部署和管理多个模型,例如同时运行 llama3 和 phi 模型
3、自定义模型
用户可以通过 Modelfile 创建自定义模型,并将其导入 Model 资源中进行部署。例如,从 GGUF 格式的模型文件中导入自定义模型。
5.1.5 Model资源的扩展功能¶
1、REST API 支持
Ollama 提供了 REST API,用户可以通过 HTTP 请求与部署的模型进行交互。例如,使用 /api/generate 接口生成文本响应
2、多模态支持
Model 资源支持多模态模型,例如处理图像和文本输入的 llava 模型
3、环境变量配置
通过环境变量(如 OLLAMA_HOST 和 OLLAMA_KEEP_ALIVE),用户可以进一步自定义模型的行为,例如调整模型的存活时间或监听地址
六、Kollama工具使用详解¶
1、kollama deploy:用于部署一个大模型
./kollama deploy phi --image=phi \
--storage-class local-path -n ollama-llms
2、kollama undeploy:用于卸载一个大模型
./kollama undeploy phi -n ollama-llms
3、kollama expose:用于暴露一个模型
./kollama expose phi -n ollama-11ms