

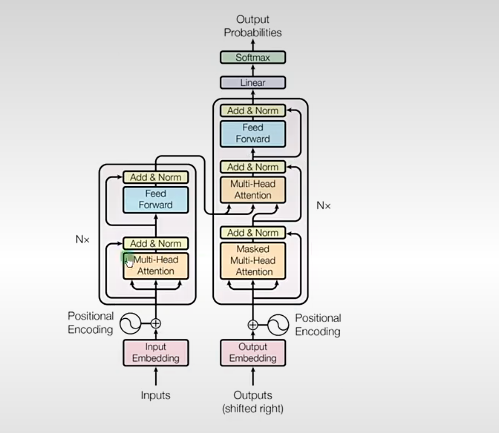
一、先看 Transformer 的整体结构¶
架构图:
示例:输入:"The cat sat on the mat"--->输出:"猫坐在垫子上"
输入阶段:
-
1)词嵌入(Word Embedding)
-
将每个单词转换为512维向量,例如:
- The→[0.2,-0.1,0.5,...]
- cat→[0.7,0.3,-0.2,...]
-
2)位置编码(Positional Encoding)
-
使用正弦和余弦函数生成位置信息,目的是让模型感知单词的顺序,同时支持更长的序列推理
```shell 代码块 Position 1 (The): [sin(1/10000^(0/512)),cos(1/10000^(0/512)),,,]
Position 2 (cat): [sin(2/10000^(0/512)),cos(2/10000^(0/512)),,,] ```
编码器层(Encoder6层堆叠):
-
多头自注意力(Mult-Head Self-Attention)
-
生成Q,K,V
- 输入向量通过线性变换生成Query(Q)、Key(K)、Value(V),每个头的维度为64(总维度512=8头×64)
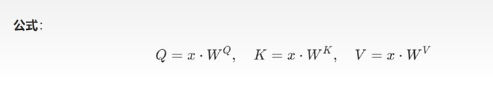
- 例如:对"cat"的输入向量

-
注意力计算
-
以"cat"为例:计算其Q与其他单词的K的点积,得到注意力分数。
-
分数经过Softmax归一化,例如:cat对sat的注意力权重较高(0.8),对The较低(0.1)。加权求和V向量,得到新的表示,包含上下文信息。
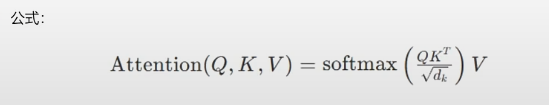
-
-
残差连接与层归一化(Add&Norm)
-
残差连接:将子层(如自注意力或FFN)的输入直接与输出相加,保留原始信息,缓解梯度消失问题。它就像“传送带”,直接传递原料(原始信息)。避免加工(子层处理)中的损耗。
Output=LayerNorm(X+Attention(X))
-
层归一化:对残差连接后的结果进行层归一化,调整数据分布,稳定训练过程,加速收敛。归一化就像是“质检员”,确保每道工序的输出规格统一。
-
前馈神经网络(Feed Forward Network,FFN)
-
FFN通过两层线性变换(中间夹非线性激活函数,如ReLU)对特征进行非线性映射。它就像是"精加工车间”,对初步处理后的半成品进行深度塑形,提升成品质量。
-
两层全连接层,激活函数为ReLU:
FFN(x)=max(0,xW1+b1)W2+b2
输出维度保持512,与输入一致
编码器层(Encoder6层堆叠):
-
输入层(Output Embedding+Positional Encoding)
-
输入为目标序列的右移版本(如翻译任务中的<SOS>猫坐在...),同样添加位置编码
-
掩码多头自注意力(Masked Multi-Head Self-Attention)
-
掩码(Mask):防止当前位置关注未来词。例如,生成第3个词时,只能关注前2个词,通过上三角矩阵屏蔽后续位置
-
计算方式与Encoder的自注意力相同,但增加掩码操作:

-
作用:处理目标序列的自注意力,确保当前位置仅关注已生成的序列部分(防止信息泄露)
编码器-解码器注意力(Encoder-Decoder Attention):
- Q来自Decoder,K和V来自Encoder的输出C
例如,生成中文"猫"时,Decoder的Q会聚焦于Encoder中cat的编码向量 * 将Encoder的输出(Key/Value)与Decoder当前状态(Query)对齐,捕捉源序列与目标序列的关联,计算方式与自注意力相同。
前馈神经网络与残差连接
- 结构与Encoder相同,通过两次残差连接和层归一化,生成最终解码结果