

一、这个智能体要完成什么¶
目标很明确:
- 获取并读取一篇新闻或博客文章全文;
- 生成一段简洁的中文摘要;
- 分别为微博和 LinkedIn 生成一段文案。
这类工作流特别适合内容团队、运营团队和技术博客维护者。
二、工作流结构¶
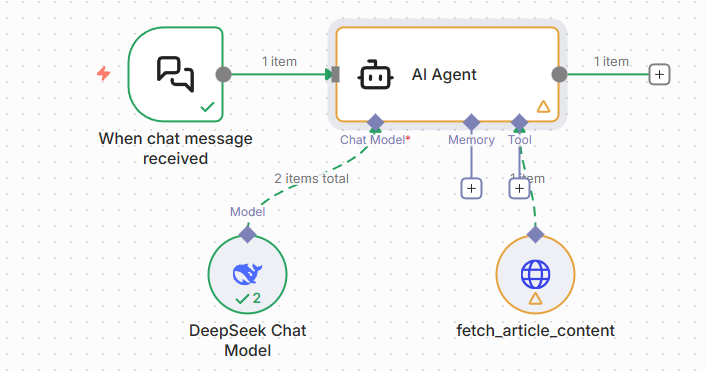
整体流程可以拆成下面几步:
- 用户通过
Chat Trigger输入文章 URL; AI Agent接收到 URL 后判断需要先抓取正文;- 调用
HTTP Request Tool获取文章纯文本; - 工具返回文章内容;
- Agent 再基于正文生成摘要、微博文案和 LinkedIn 文案;
- 最终结果以结构化 JSON 返回。
工作流示意:
三、核心 Prompt 怎么写¶
这类 Agent Prompt 的关键,是把职责说清楚,并且要求它最终输出结构化结果。
可以参考这样的写法:
你是一个专业的内容营销专家。你的任务是分析用户提供的文章URL,并完成以下三项工作:
1. 使用 `fetch_article_content` 工具获取文章全文。
2. 阅读并理解文章内容,生成一段简洁中文摘要(不超过100字)。
3. 基于文章内容,为微博和 LinkedIn 平台分别创作一段吸引人的文案。
请将最终结果以 JSON 格式返回:
{
"summary": "文章摘要",
"weibo_post": "微博文案",
"linkedin_post": "LinkedIn文案"
}
如果无法获取文章内容,请返回错误信息。
四、工具怎么配置¶
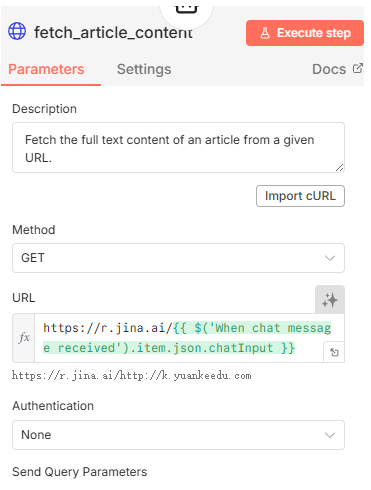
这个例子里,关键工具是一个用于抓取文章正文的 HTTP 请求工具。
思路是使用:
https://r.jina.ai/<article-url>
也就是把用户输入的原始文章链接交给一个可提取纯文本的服务,再把结果返回给 Agent。
Prompt 里对应的工具描述可以写成:
Fetch the full text content of an article from a given URL.
这样模型会更容易判断该什么时候调用工具。
五、为什么这个案例有代表性¶
它体现了智能体工作流里非常经典的一条链路:
- 输入是自然语言;
- 中间通过工具补足外部信息;
- 最后输出不是随意聊天,而是结构化结果。
这比单纯的“问答机器人”更接近真实业务场景。
六、可以怎么扩展¶
在这个案例上继续往前走,很容易扩展出更多能力:
- 自动同步到微信公众号草稿;
- 自动写邮件标题和摘要;
- 自动生成短视频脚本;
- 自动把结果存进 Notion、飞书或数据库;
- 自动区分不同平台的文风和字数。
七、一个实战建议¶
如果你想让 n8n 里的 AI Agent 更稳定,最好让它只负责“判断和生成”,而把真正的抓取、存储、通知、调度交给明确的工具节点和工作流节点去做。这样整套系统会比完全依赖模型推理更可靠。