

一、环境准备¶
说明:安装Prometheus+alertmanager的机器配置如下
CPU:2C
内存:4G
磁盘:40G
系统:Rocky9
6.1.1 安装Prometheus¶
下载包
wget https://github.com/prometheus/prometheus/releases/download/v3.5.0/prometheus-3.5.0.linux-amd64.tar.gz
如果该链接无法下载,可以使用代理
curl -L -xt.lishiming.net:15888 'https://github.com/prometheus/prometheus/releases/download/v3.5.0/prometheus-3.5.0.linux-amd64.tar.gz' -O prometheus-3.5.0.linux-amd64.tar.gz
解压
mv prometheus-3.5.0.linux-amd64.tar.gz /opt
cd /opt
tar zxf prometheus-3.5.0.linux-amd64.tar.gz
ln -s /opt/prometheus-3.5.0.linux-amd64 /opt/prometheus
编辑systemd脚本
vi /lib/systemd/system/prometheus.service ##内容如下
[Unit]
Description=prometheus service
After=network.target
[Service]
User=prometheus
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml \
--storage.tsdb.path=/var/lib/prometheus
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
创建用户和目录
useradd -s /sbin/nologin prometheus
mkdir /var/lib/prometheus
chown prometheus /var/lib/prometheus
启动服务
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
查看进程和端口
ps aux |grep prometheus
netstat -ltnp|grep prometheus ##能看到9090
6.1.2 安装node_exporter¶
下载包
cd /opt/
wget https://github.com/prometheus/node_exporter/releases/download/v1.10.0/node_exporter-1.10.0.linux-amd64.tar.gz
解压
tar zxvf node_exporter-1.10.0.linux-amd64.tar.gz
ln -s /opt/node_exporter-1.10.0.linux-amd64/ /opt/node_exporter
编辑node_exporter服务管理脚本
vi /lib/systemd/system/node_exporter.service #内容如下
[Unit]
Description=node-exporter service
After=network.target
[Service]
User=prometheus
KillMode=control-group
Restart=on-failure
RestartSec=60
ExecStart=/opt/node_exporter/node_exporter\
--web.listen-address=:9100\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat
ExecStop=/bin/kill -QUIT $MAINPID
[Install]
WantedBy=multi-user.target
创建用户
id prometheus 2>/dev/null || useradd -s /sbin/nologin prometheus
chown -R prometheus /opt/node_exporter/
启动服务
systemctl daemon-reload
systemctl start node_exporter
systemctl enable node_exporter
查看进程和端口
ps aux |grep node_exporter
netstat -ltnp |grep node_exporter ##能看到9100
修改prometheus服务端配置文件,增加node target
vi /opt/prometheus/prometheus.yml
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node"
static_configs:
## <your-monitor-server-ip>为node_exporter的IP
- targets: ["<your-monitor-server-ip>:9100"]
重启服务
systemctl restart prometheus
浏览器访问 http://<your-monitor-server-ip>:9090/targets
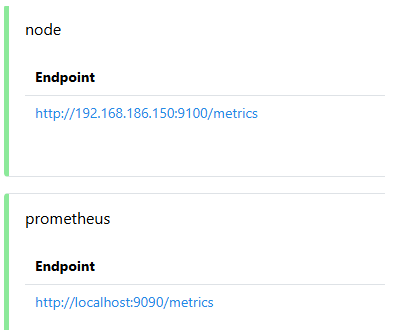
6.1.3 安装Alertmanager¶
下载包
官网地址: https://github.com/prometheus/alertmanager/releases/,选择最新的包
wget https://github.com/prometheus/alertmanager/releases/download/v0.29.0/alertmanager-0.29.0.linux-amd64.tar.gz
解压到/opt下
tar zxf alertmanager-0.29.0.linux-amd64.tar.gz -C /opt/
ln -s /opt/alertmanager-0.29.0.linux-amd64/ /opt/alertmanager
创建用户并改权限
id alertmanager 2>/dev/null || useradd -s /sbin/nologin alertmanager
chown -R alertmanager /opt/alertmanager/
以systemd方式启动alertmanager
vi /lib/systemd/system/alertmanager.service #内容如下
[Unit]
Description=alertmanager service
After=network.target
[Service]
User=alertmanager
ExecStart=/opt/alertmanager/alertmanager --config.file=/opt/alertmanager/alertmanager.yml
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -QUIT $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
创建/data/目录
## Alertmanager服务会自动创建/data目录,由于我们定义启动服务用户为alertmanager,所以它没权限创建
mkdir /data/
chown -R alertmanager /data/
启动服务
systemctl daemon-reload
systemctl start alertmanager.service
systemctl enable alertmanager.service
查看进程和端口
ps aux|grep alertmanager
netstat -ltnp |grep alert
浏览器访问
http://<your-monitor-server-ip>:9093
6.1.4 配置Prometheus告警¶
告警的流程: exporter ---> prometheus (告警规则)---> alertmanager(处理告警,分组、抑制、静默)---> user(通过邮件、微信、钉钉等)
1、在Prometheus配置告警规则
vi /opt/prometheus/prometheus.yml
开启rule_file
rule_files:
- "host_rules.yml"
vi /opt/prometheus/host_rules.yml
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: 1 - rate(node_cpu_seconds_total{mode="idle"}[1m]) > 0.8
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
重启Prometheus
systemctl restart prometheus
查看Alerts,能看到已生效配置文件和规则
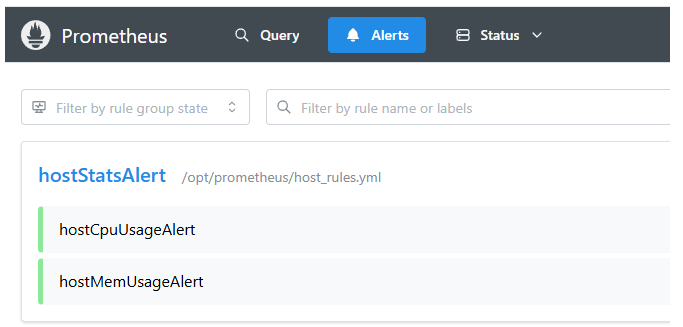
如需接收告警,还需要再Alertmanager里配置,具体参考文档 https://app.yinxiang.com/fx/2cb8d00e-5fc7-464a-82ae-0d12e1223726
6.2 部署Prometheus-mcp¶
项目地址:https://github.com/tjhop/prometheus-mcp-server
Docker方式启动服务:
docker run -d -p 8080:8080 ghcr.io/tjhop/prometheus-mcp-server:latest --prometheus.url "http://<your-server-ip>:9090" --mcp.transport "http" --web.listen-address ":8080"
注意,需要在Prometheus那台机器上运行该容器,并且我这里假设Prometheus是二进制方式启动,并非容器化,172.17.0.1为宿主机docker0的ip,这样容器内部可以通过该ip访问到宿主机
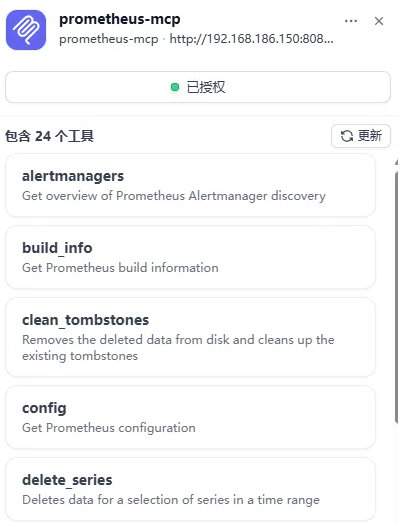
6.3 Dify中配置Prometheus MCP¶
1、服务端点URL:http://<host>:8080/mcp(这里host地址就是你部署Prometheus MCP服务的IP地址)
2、名称和服务器标识符:prometheus-mcp
3、认证:无需认证
6.4 在Dify中创建Agent应用¶
设置提示词:
你是企业级 AIOps 智能体,能够根据用户自然语言意图,
自动分析、组合 PromQL,并通过 prometheus-mcp 工具调用进行查询。
任务包括但不限于:
- 性能巡检(CPU、内存、磁盘、网络)
- Pod / Node 健康分析
- 告警根因定位
- 指标趋势分析
- 指标对比 / 环比
如果需要查询 Prometheus,请你主动调用相应的 MCP 工具。
请在给出结论时说明推理逻辑,输出可执行建议。
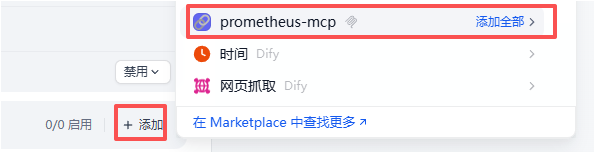
添加工具:
示例1
查看所有target
示例2
查看所有告警规则
示例3
查看过去1小时内有无异常的指标
示例4
现在有哪些告警处于 firing 状态?
示例5
过去 1 小时内触发过哪些告警?是否已经恢复?
示例6
过去 1 小时内是否存在异常波动或明显异常的指标?
示例7
过去 1 小时内是否有节点 CPU 使用率异常升高?
示例8
是否存在磁盘使用率超过 85% 的节点?
示例9
当前 CPU 使用率最高的 5 个节点是哪些?
示例10
按当前磁盘增长速度,是否有节点在 7 天内可能磁盘耗尽?
示例11
帮我做一次 Prometheus 集群的健康巡检
示例12
现在业务访问变慢了,从 Prometheus 指标上看可能是什么