

一、Filebeat¶
在早期的ELK架构中,日志收集均以Logstash为主,Logstash负责收集和解析日志,它对内存、CPU、IO资源的消耗比较高,但是Filebeat所占系统的CPU和内存几乎可以忽略不计。
由于Filebeat本身是比较轻量级的日志采集工具,因此Filebeat经常被用于以Sidecar的形式配置在Pod中,用来采集容器内程序输出的自定义日志文件。当然,Filebeat同样可以采用DaemonSet的形式部署在Kubernetes集群中,用于采集系统日志和程序控制台输出的日志。至于Filebeat为什么采用DaemonSet的形式部署而不是采用Deployment和StatefulSet部署,原因有以下几点:
- 收集节点级别的日志:Filebeat需要能够访问并收集每个节点上的日志文件,包括系统级别的日志和容器日志。Deployment和STS的主要目标是部署和管理应用程序的Pod,而不是关注节点级别的日志收集。因此,使用DaemonSet更适合收集节点级别的日志
- 自动扩展:Deployment和STS旨在管理应用程序的副本数,并确保所需的Pod数目在故障恢复和水平扩展时保持一致。但对于Filebeat来说,并不需要根据负载或应用程序的副本数来调整Pod数量。Filebeat只需在每个节点上运行一个实例即可,因此使用DaemonSet可以更好地满足这个需求
- 高可用性:Deployment和STS提供了副本管理和故障恢复的机制,确保应用程序的高可用性。然而,对于Filebeat而言,它是作为一个日志收集代理来收集日志,不同于应用程序,其故障恢复的机制和需求通常不同。使用DaemonSet可以确保在每个节点上都有一个运行中的Filebeat实例,即使某些节点上的Filebeat Pod不可用,也能保持日志收集的连续性
Fluentd和Logstash可以将采集的日志输出到Elasticsearch集群,Filebeat同样可以将日志直接存储到Elasticsearch中,但是为了更好地分析日志或者减轻Elasticsearch的压力,一般都是将日志先输出到Kafka,再由Logstash进行简单的处理,最后输出到Elasticsearch中。
优点: 占用系统的CPU和内存小;
可以更好地分析日志;
缺点:
依赖Elasticsearch,维护难度和资源使用都是偏高;
Filebeat+Kafka+Logstash+ES架构解析:
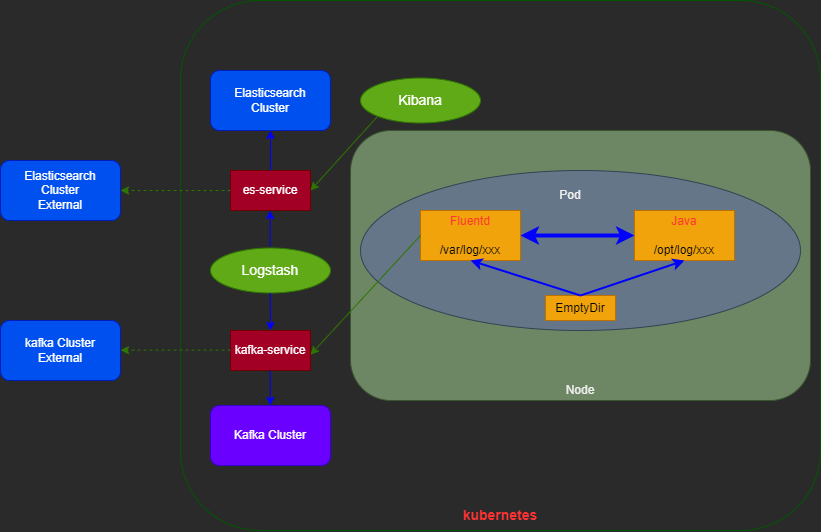
1.在k8s集群的每个pod都新起两个容器(Filebeat和应用容器-java),同时配置一个类型为EmptyDir的volume,将宿主机的文件目录挂载到两个容器中,达到日志共享目的。 2.Filebeat利用轻量级特性将日志文件打包给Kafka 3.Logstash获取到Kafka的日志信息,并进行解析。 4.解析完成后,数据存储到ES 5.Kibana从ES中查看日志数据
二、Loki¶
无论是ELK、EFK还是Filebeat,都需要用到Elasticsearch来存储数据,而Elasticsearch维护难度和资源使用都是偏高的。所以一个更轻量的日志收集平台-Loki应运而生。
Loki是Grafana Labs开源的一个支持水平扩展、高可用、多租户的日志聚合系统。

涉及如下组件:
- Loki:主服务器,负责日志的存储和查询,参考了Prometheus的服务发现机制,将标签添加到日志流,而不是像其他平台一样进行全文索引。
- Promtail:负责收集日志并将其发送给Loki,主要用于发现采集目标以及添加对应Label,最终发送给Loki。
- Grafana:用来展示或查询相关日志,可以在页面查询指定标签Pod的日志。
Loki不对日志进行全文索引,仅索引相关日志的元数据,所以Loki操作起来更简单、更省成本。而且Loki是基于Kubernetes进行设计的,可以很方便地部署在Kubernetes上,并且对集群的Pod进行日志采集,采集时会将Kubernetes集群中的一些元数据自动添加到日志中,让技术人员可以根据命名空间、标签等字段进行日志的过滤,可以很快速地定位到相关日志。
优点:
轻量化、操作简单、省成本
缺点:
相对其他技术栈功能不是很灵活