- 100,000+ Pods
- 1300+ Nodes
- 3集群(单:11Master + 17ETCD)
- ToC服务行业
一、遇到的问题¶
- Apiserver调度,延迟问题;
- Controller 不能及时从 API Server 感知到最新的变化,处理的延时较高;
- Scheduler 延迟高、吞吐低,无法适应业务日常需求;
- ETCD架构设计不合理/ETCD稳定性/ETCD性能无法满足业务;
- 发生异常重启时,服务的恢复时间需要几分钟;
- ......
二、优化提升之路¶
三、硬件/网络/存储/架构等¶
虚拟机(或物理服务器)层面的优化
- 旧换新:使用较久的服务全部更新为新款服务器,针对类型采购最新不同类型的资源。
- 调整虚拟机配置:增加虚拟机的内存、CPU 核心数等资源,以满足高并发负载的需求。
- 使用高性能的虚拟化技术:选择性能较好的虚拟机管理器(如KVM、Xen等),充分利用硬件资源。
- 宿主资源超卖:比如将一个实际只有 48 核的宿主上报资源给 apiserver 时上报为 60 核,以此来对宿主进行资源超卖。
硬件层面的优化:
- 多核处理器:使用多核处理器可以提高系统的处理能力,使其能够更好地应对高并 发负载。
- 高速缓存:充分利用硬件的高速缓存,减少数据访问的延迟。
- 高性能网络接口:采用高性能的网卡和交换机,提供更快的网络传输速度和更低的延迟。
网络层面的优化:
- 负载均衡:采用负载均衡设备或技术,将请求均匀地分布到多台服务器上,提高整体的并发处理能力。
- 增加带宽:提高网络带宽可以支持更多的并发连接,并减少网络传输的瓶颈。
- 优化网络协议:使用较低延迟和高吞吐量的网络协议,如使用GRPC代替HTTP, QUIC代替TCP等。
存储层面的优化:
- 使用高性能的存储设备:采用SSD 硬盘或 NVMe 存储设备,提高数据的读写速度和响应时间。
-
数据缓存:使用缓存技术(如 Redis、Memcached 等),减少后端存储的访问压力。
-
数据库优化:对数据库进行索引优化、查询优化等,提高数据库的读写性能。
架构层面的优化:
- 异步处理:采用异步处理模式,如使用消息队列或事件驱动架构等,将请求的处理过程解耦,提高系统的并发能力。
- 分布式架构:使用分布式架构,将负载分散到多个节点上,提高系统的横向扩展性能。
- 水平拆分:根据负载情况和业务需求,将系统按照不同的功能或模块进行水平拆分,以提高并发处理能力。
四、内核层面¶
增大内核选项配置 /etc/sysctl.conf:
1)一般如果遇到文件句柄达到上限时,会碰到 "Too many open files" 或者Socket/File: Can’t open so many files 等错误:
# max-file 表示系统级别的能够打开的文件句柄的数量
fs.file-max=1000000
2)配置 arp cache 大小,当内核维护的arp表过于庞大时候,可以考虑优化:
# 存在于ARP高速缓存中的最少层数,如果少于这个数,垃圾收集器将不会运行。缺省值是128。
net.ipv4.neigh.default.gc_thresh1=1024
# 保存在 ARP 高速缓存中的最多的记录软限制。垃圾收集器在开始收集前,允许记录数超过这个数字 5 秒。缺省值是 512。
net.ipv4.neigh.default.gc_thresh2=4096
# 保存在 ARP 高速缓存中的最多记录的硬限制,一旦高速缓存中的数目高于此,垃圾收集器将马上运行。缺省值是1024。
net.ipv4.neigh.default.gc_thresh3=8192
3) conntrack 是指针对连接跟踪(Connection Tracking)进行的性能优化措施:
# 允许的最大跟踪连接条目,是在内核内存中netfilter可以同时处理的“任务”(连接跟踪条目)
net.netfilter.nf_conntrack_max=10485760
# 哈希表大小(只读)(64位系统、8G内存默认 65536,16G翻倍,如此类推)
net.core.netdev_max_backlog=10000
# 每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.netfilter.nf_conntrack_tcp_timeout_established=300
net.netfilter.nf_conntrack_buckets=655360
4)监听文件系统上的事件(如文件创建、修改、删除等),并在事件发生时通知相应的应用程序:
# 默认值: 128 指定了每一个real user ID可创建的inotify instatnces的数量上限
fs.inotify.max_user_instances=524288
# 默认值: 8192 指定了每个inotify instance相关联的watches的上限
fs.inotify.max_user_watches=524288
五、Etcd性能优化¶
5.1 架构层面¶
- 1、搭建高可用的etcd集群, 集群规模增大时可以自动增加etcd节点;
5.2 硬件层面¶
- 1、etcd 采用本地 ssd 盘作为后端存储存储;
- 2、etcd 独立部署在非 k8s node 上;
- 3、etcd 快照(snap)与预写式日志(wal)分盘存储;
1)Etcd对磁盘写入延迟非常敏感,因此对于负载较重的集群,etcd一定要使用 Local SSD 或者高性能云盘。可以使用fio测量磁盘实际顺序 IOPS。
$ fio -filename=/dev/sda1 -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=60G -numjobs=64 -runtime=10 -group_reporting -name=file
2)由于etcd必须将数据持久保存到磁盘日志文件中,因此来自其他进程的磁盘活动可能会导致增加写入时间,结果导致etcd请求超时和临时leader丢失。
因此可以给etcd进程更高的磁盘优先级,使etcd服务可以稳定地与这些进程一起运行。
$ ionice -c2 -n0 -p $(pgrep etcd)
3)默认etcd空间配额大小为 2G,超过 2G 将不再写入数据。通过给etcd配置 --quota-backend-bytes 参数增大空间配额,最大支持 8G。
--quota-backend-bytes 8589934592
4)如果 etcd leader 处理大量并发客户端请求,可能由于网络拥塞而延迟处理follower对等请求。在follower 节点上可能会产生如下的发送缓冲区错误的消息:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full
可以通过提高etcd对于对等网络流量优先级来解决这些错误。在 Linux 上,可以使用 tc对等流量进行优先级排序
$ tc qdisc add dev eth0 root handle 1: prio bands 3
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip
sport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip
dport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip
sport 2379 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip
dport 2379 0xffff flowid 1:1
5)为了在大规模集群下提高性能,可以将events存储在单独的 ETCD 实例中,可以配置kube-apiserver参数:
##添加 etcd 配置
vim /etc/kubernetes/manifests/kube-apiserver.yaml
##新增如下,第一行代表着当前的主ETCD,第二块代表着 Event事件拆分到的 Etcd 集群
--etcd-servers="http://etcd1:2379,http://etcd2:2379,http://etcd3:2379" \
--etcd-servers-overrides="/events#http://etcd4:2379,http://etcd5:2379,http://etcd6:
2379"
6)目前的解决方案是使用 etcd operator 来搭建 etcd 集群,它是一个感知应用状态的控制器,通过扩展Kubernetes API来自动创建、管理和配置应用实例。
etcd operator 有如下特性:
- ceate/destroy:自动部署和删除 etcd 集群,不需要人额外干预配置。
- resize:可以动态实现 etcd 集群的扩缩容。
- backup:支持etcd集群的数据备份和集群恢复重建
- upgrade:可以实现在升级etcd集群时不中断服务。
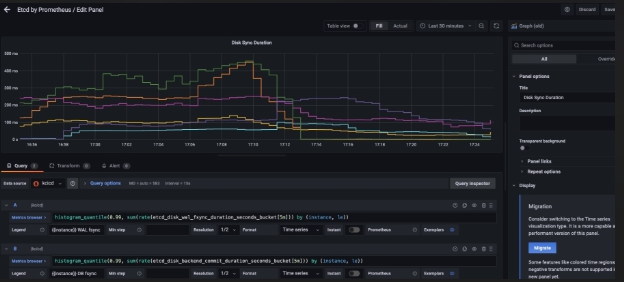
7)etcd 优化前后对比(2019年)
优化前
08:42:37 node1 etcd[1091]: read-only range request "key:\"/registry/minions/node1\" " with result "range_response_count:1 size:14068" took too long (107.736306ms) to execute
08:42:37 node1 etcd[1091]: read-only range request "key:\"/registry/pods/xxx/p-cfhlvsaf16letp8btsp0-fetch--rw-7qrpm\" " with result "range_response_count:1 size:20887" took too long (103.499181ms) to execute
08:42:37 node1 etcd[1091]: read-only range request "key:\"/registry/pods/xxx/p-cfhlvi2f16letp8btsmg-docker-build-rbrzl-pod-fjk2l\" " with result "range_response_count:1 size:22666" took too long (115.939841ms) to execute
08:42:37 node1 etcd[1091]: read-only range request "key:\"/registry/tekton.dev/pipelines/xxx/p-cbqcugeb23tefrmhs5jg\" " with result "range_response_count:1 size:12536" took too long (157.681896ms) to execute
08:42:37 node1 etcd[1091]: read-only range request "key:\"/registry/pods/xxx/p-cfhlvsaf16letp8btsp0-fetch--rw-7qrpm\" " with result "range_response_count:1 size:20853" took too long (147.333596ms) to execute
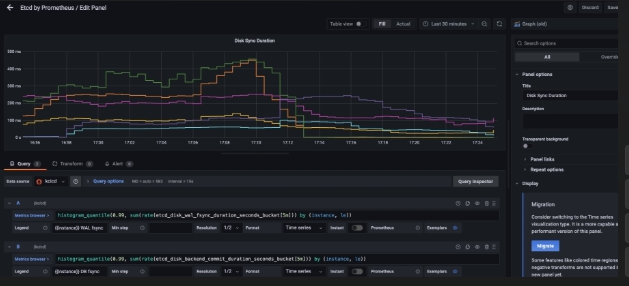
优化后