一、数据类型选择不合理¶
1、选择合适的类型
当一个可以聚合的内容分开存储时,总共占用了( 64+57+61) =182字节,改为 hash存储时,占用了 98字 节。
2、压缩列表的条件: "列表中元素数量 <512个 " && "列表中所有字符串对象都不足 64字节 "

二、过期 key订阅¶
现象:
监听过期事件处理业务,如订单 30分钟过期,因为程序没有再访问 master,没有触发删除,导致系统订单一 直未关闭,库存未释放。
redis内部机制:
redis产生 expired的时间为过期 key被删除的时候,而不是 ttl变为 0的时候。
代码在:
notifyKeyspaceEvent(NOTIFY_EXPIRED, "expired",key,db->id);
1,__keyspace@db__:key expired
2, __keyevent@db__:expired key
redis订阅过期事件是订阅的 __keyevent@db__:expired 。
结论:
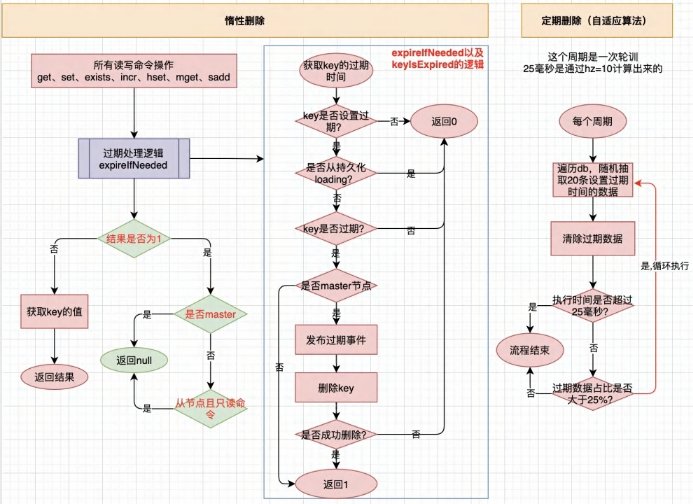
当一个键过期时, Redis并不会主动通知订阅者。 redis产生 expired的事件为过期 key被删除的时候,而不 是 ttl变为 0的时候。而删除是由两种过期键删除策略完成的,一种是定期删除,一种是惰性删除。会在适当的 时候自动删除过期的键,也有可能不会触发删除。这就导致无法收到过期事件通知。从而引发生产事故。
三、大 key问题¶
key过大会引起以下的问题:
- 占用网络 IO和 cpu,阻塞,比如有的 key里存储十几 MB的数据,多次查询,会阻塞其他的操作请求;
- 内存挤占过多,甚至会把未失效的清掉,比如自己用 zset做的限流、数据没有及时删除,导致占用内存过 多;
- del删除也会阻塞(使用异步删除 unlink)
如何发现大 key?
- 实时检测:通过 redis-cli --bigkeys检测
- 离线检测:通过 redis-rdb-tools工具对备份的 rdb进行分析
- redis-rdb-tools工具
redis-rdb-tools 是一个 python 的解析 rdb 文件的工具,在分析内存的时候,我们主要用它生成内存 快照。
(1)生成 rdb文件
(2)分析 rdb文件,并将结果写入到 csv文件中
rdb -c memory dump.rdb > dump-rdb.csv
输出字段说明:
- database : key在 redis的 db
- type : key类型
- key : key值
- size_in_bytes : key的内存大小 (byte)
- encoding : value的存储编码形式
- num_elements : key中的 value的个数
- len_largest_element : key中的 value的长度
- expiry : key过期时间
(3)'直接分析 csv文件获取大 key' or '将 csv文件的数据导入到 mysql数据库进行分析 '
解决并避免
- 异步删除
- 选择合适的数据库
- 选择合适的数据结构
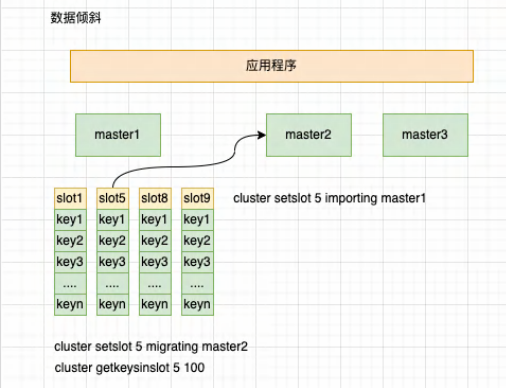
四、数据倾斜¶
现象:
rediscluster大量的 key路由到其中一个 master节点,导致该节点 cpu,内存、 qps升高
数据倾斜的原因:
1、大 key的出现 2、数据的写入机制,一般都是 hash后不均匀出现的 3、数据迁移或扩容
解决:
1、排查集群中是否存在大 key,对 bigkey拆分; 2、将数据量大的 slot迁移,迁移一部分到其他 master节点: 3、热点数据,利用分片算法的特性,对 key进行打散处理
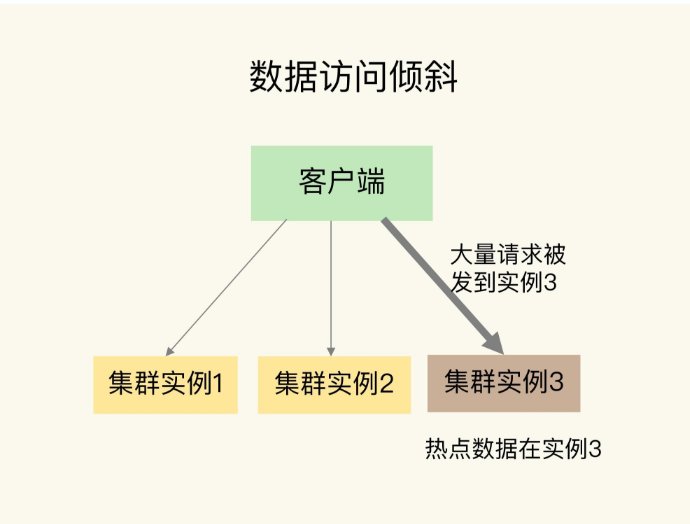
五、流量倾斜¶
流量倾斜一般是指 redis集群中某个节点的流量远远大于平均流量值。
原因:
- 实例上存在热点数据
如何解决 &避免
只读的热点数据:热点数据复制多份,每一个数据副本的 key 中增加一个随机前缀,让其被映射到不同的 Slot 中
有读有写热点数据:升配
六、redis慢日志¶
我们在分析 redis变慢的时候,除了看 cpu,看 io,还有一种情况,就是啥都没问题,就是慢。那我们可以 看看 redis的慢日志。
redis的慢日志是 redis提供的一个简单的慢命令统计记录功能,它会把命令执行时间超过 slowlog-log- slower-than 纪录到一个列表中,该列表通过 slowlog-max-len 控制长度。
配置:
-- 设置20000微妙
config set slowlog-log-slower-than 20000
-- 设置保留1000条
config set slowlog-max-len 1000
config rewrite
-- 示例:
[root@OPS-9-78 ~]# redis-cli -p 6400
-- 设置20000微妙
127.0.0.1:6400> config set slowlog-log-slower-than 20000
OK
-- 设置保留1000条
127.0.0.1:6400> config set slowlog-max-len 1000
OK
127.0.0.1:6400> config rewrite
OK
-- 查看慢日志
127.0.0.1:6400> slowlog get 1
1) 1) (integer) 1
2) (integer) 1686971278
3) (integer) 108129
4) 1) "config"
2) "rewrite"
5) "127.0.0.1:49489"
6) ""
-- 查看日志列表的长度
127.0.0.1:6400> slowlog len
(integer) 2
-- slowlog 重置
127.0.0.1:6400> slowlog reset
OK
127.0.0.1:6400> slowlog len
(integer) 0
七、波动的响应延迟¶
redis客户端访问 redis经过了网络, loop排队,命令执行,这三块都有可能导致 redis server的响应延迟。 我们这节重点分析下 loop排队中的延迟。
7.1 怎么查看延迟?¶
7.1.1 第一种方式¶
Redis 2.6版本的时候,引入了一个看门狗( watchdog)工具,这个工具可以用于诊断 redis的延迟问题。
watchdog 只是用来调试程序的,会阻塞 server,耗时会比较高,生产不要使用。
-- 设置延迟间隔时间
127.0.0.1:6400> CONFIG SET watchdog-period 300
OK
-- 关闭watchdog
127.0.0.1:6400> CONFIG SET watchdog-period 0
-- 官网给的例子
[8547 | signal handler] (1333114359)
--- WATCHDOG TIMER EXPIRED ---
/lib/libc.so.6(nanosleep+0x2d) [0x7f16b5c2d39d]
/lib/libpthread.so.0(+0xf8f0) [0x7f16b5f158f0]
/lib/libc.so.6(nanosleep+0x2d) [0x7f16b5c2d39d]
/lib/libc.so.6(usleep+0x34) [0x7f16b5c62844]
./redis-server(debugCommand+0x3e1) [0x43ab41]
./redis-server(call+0x5d) [0x415a9d]
./redis-server(processCommand+0x375) [0x415fc5]
./redis-server(processInputBuffer+0x4f) [0x4203cf]
./redis-server(readQueryFromClient+0xa0) [0x4204e0]
./redis-server(aeProcessEvents+0x128) [0x411b48]
./redis-server(aeMain+0x2b) [0x411dbb]
./redis-server(main+0x2b6) [0x418556]
/lib/libc.so.6(__libc_start_main+0xfd) [0x7f16b5ba1c4d]
./redis-server() [0x411099]
------
例子中 DEBUG SLEEP 命令是用于阻塞服务器的。在不同的阻塞背景下,堆栈信息会有不同
7.1.2 第二种方式¶
redis从 2.8.7 版本开始, redis-cli 命令提供了 –intrinsic-latency 选项,可以用来监测和统计测试期间内的 最大延迟,这个延迟可以作为 Redis 的基线性能
[root@OPS-9-78 ~]# redis-cli -p 6400 --intrinsic-latency 120
Max latency so far: 1 microseconds.
Max latency so far: 7 microseconds.
Max latency so far: 41 microseconds.
Max latency so far: 42 microseconds.
Max latency so far: 49 microseconds.
Max latency so far: 98 microseconds.
Max latency so far: 341 microseconds.
Max latency so far: 818 microseconds.
Max latency so far: 1244 microseconds.
Max latency so far: 1621 microseconds.
1621249297 total runs (avg latency: 0.0740 microseconds / 74.02 nanoseconds per run).
Worst run took 21900x longer than the average latency.
7.2 cpu架构对 redis性能的影响¶
redis是典型的 cpu密集型应用, cpu的性能对 redis的影响还是比较大的。
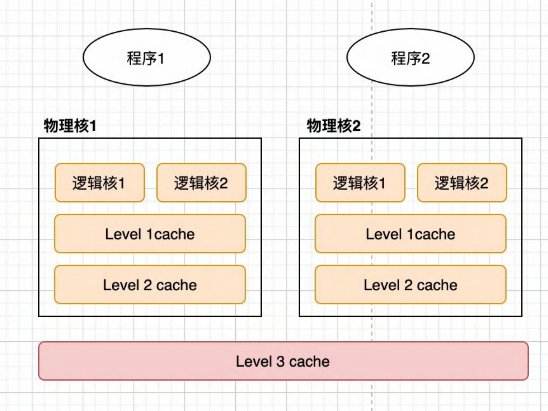
- 1个 cpu处理器一般有多个运行核心,一个运行核心称为一个物理核,每个物理核都可以运行程序
- 每个物理核都拥有私有的一级缓存( Level 1 cache 包括一级指令缓存和一级数据缓存)访问延迟在 10ns,以及私有的二级缓存( Level 2 cache 访问延迟在 100ns)
-
一个 CPU有一个三级缓存,在一个 cpu中的不同的物理核会共享一个共同的三级缓存( Level 3 cache)
-
每个物理核通常会运行两个逻辑核(超线程)
- 应用程序在 1个 cpu内访问叫本地内存访问,切到另一个 cpu上运行,需要调用原来的数据叫远端内存访问
7.2.1 多核 CPU对 redis的性能影响¶
当 redis运行的时候, cpu进行上下文切换时,应用程序由 cpu的 A物理核切换到 B物理核,应用程序的运行时信息需要从 L3或从内存中被重新加载到 B 物理核的 L1、 L2缓存中,就会导致 redis的延迟增加。(虽然是微秒级,但是在流量高峰会出现毛刺)
7.2.2 多核 cpu下的优化¶
既然这样,那我们就想办法让 redis运行在一个物理核上,就可以避免因 cpu切换带来的延迟问题。
Note: 绑定以后主线程、子进程、后台线程共享使用一个物理核,如果能将子进程和后台线程单独绑 定物理最好(需要修改源码)
幸好 linux给我们提供了一个命令 taskset
taskset命令用于设置进程(或 线程)的处理器亲和性( Processor Affinity),可以将进程(或 线程)绑定到特定的一个或多个 CPU上去执行,而不允许将进程(或 线程)调度到其他的 CPU上。
先通过 lscpu查看下核的编号(一定要注意 NUMA架构下 cpu核的编号方法)
[root@OPS-9-78 6400]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 1
座: 4
NUMA 节点: 1
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 79
型号名称: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
步进: 1
CPU MHz: 2199.998
BogoMIPS: 4399.99
超管理器厂商: VMware
虚拟化类型: 完全
L1d 缓存: 32K
L1i 缓存: 32K
L2 缓存: 256K
L3 缓存: 25600K
NUMA 节点 0 CPU(s): 0-3,8-11 # NUMA架构下节点 0是一个物理核 ,第一个逻辑核的 cpu编号是 0到 3, 第二个逻辑核的 cpu编号是 8~11
NUMA 节点 1 CPU(s): 4-7,12-15 # NUMA架构下节点 1是一个物理核 ,第一个逻辑核的 cpu编号是 4到 7, 第二个逻辑核的 cpu编号是 12~15
将 redis绑定到一个物理核上的两个逻辑核上,
taskset -c 0,8 ./redis-server
7.3 内存交换¶
swap对于操作系统来比较重要,当物理内存不足时,可以将一部分内存页进行 swap操作,已解燃眉之 急。 swap的空间是由磁盘提供。
内存交换( swap)对 redis来说是致命的, redis保证高性能的一个重要的前提是所有的数据在内存中。如果操作系统把 redis使用的部分内存换到硬盘,由于内存与磁盘的读写速度是数量级的差异,会导致发生内存交换后的 redis性能急剧下降。
7.3.1 检查内存交换¶
查询 redis的进程 id
ps -ef|grep redis
根据进程号查询内存交换信息
cat /proc/12875/smaps |grep Swap Swap: 0 kB
Swap: 0 kB
Swap: 4 kB
Swap: 0 kB
Swap: 0 kB
7.3.2 屏蔽 swap¶
配置 swap
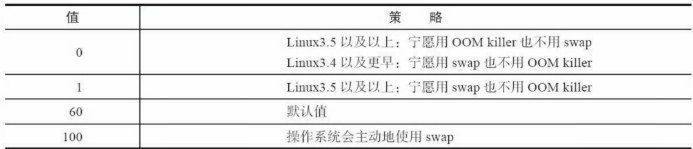
echo 0 > /proc/sys/vm/swappiness
7.4 内存大页¶
linux内核从 2.6.38开始支持内存大页机制。该机制支持 2MB大小的内存页分配,而常规的内存页分配是按 4kb来的。
为什么内存大页会影响延迟呢?这就要说到 fork机制了。我们都知道 fork以后,一旦数据要修改,并不会 在原来的内存上修改,而是 copy一份,然后再进行修改。
如果采用内存大页,即使客户端请求只修改 200B的数据, redis 也需要 copy2MB的大页,如果是 4kb的 页,只会 copy 4kb。这在高并发的时候就能体现出来。
-- 关闭系统大页
echo never /sys/kernel/mm/transparent_hugepage/enabled
八、删除数据后,内存占用率无法下降¶
现象:
删除 redis数据后,用 top统计时,发现 redis占用了很多内存
原因: 内存碎片
例 : 假设,我们的 redis由 100MB内存,我们保存了 95条占用 1mb的 key,共计占用 95mb,这个时候,我们添 加一个 10mb的 key,按道理来说我们淘汰 5个 1mb的 key就行,实际情况则是不行。
如何清理?
#相关配置参数
-- 开启自动内存清理
config set activedefrag yes
-- 内存碎片的字节数达到 100mb,开始清理
config set active-defrag-ignore-bytes 100mb
-- 内存碎片空间占操作系统分配给 redis的总空间比例达到 10%时,开始清理
config set active-defrag-threshold-lower 10
-- 表示自动清理过程所用 cpu时间的比例不低于 25%
active-defrag-cycle-min 25
-- 表示自动清理过程所用 cpu时间的比例不高于 75%,一旦超过,就停止清理,以避免影响 redis
active-defrag-cycle-max 75
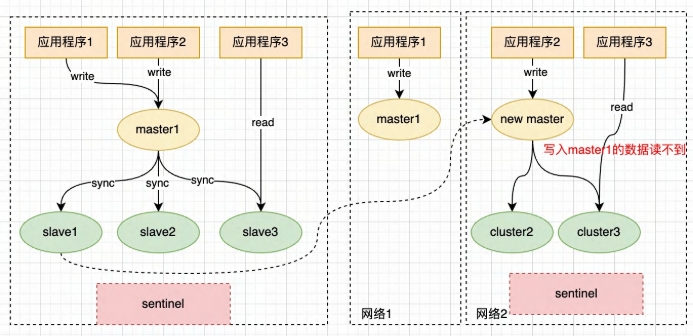
九、脑裂¶
Redis脑裂( Split-Brain)是指在 Redis集群中发生网络分区(网络故障、网络延迟等)导致集群节点之间 无法正常通信,从而导致集群分裂成多个独立的子集,每个子集都认为自己的主节点。
脑裂可能导致以下问题:
1、数据冲突 2、数据丢失 3、服务不可用
#如何避免
在主库上设置
旧版本(3.2及以下)
min-slaves-to-write 3
min-slaves-max-lag 10
新版本(4.0及以上)
min-replicas-to-write 3 最少从库数量
min-replicas-max-lag 10 从库最大延迟时间
任一条件不满足,主库将不再接收请求