

一、有哪些日志需要收集管理?¶
在日常使用控制过程中,一般需要收集的日志为以下几类:
- 服务器系统日志
- /var/log/messages
- /var/log/kube-xxx.log
- Kubernetes组件日志(/var/log/kube.*)
- kube-apiserver日志
- kube-controller-manager日志
- kube-scheduler日志
- kubelet日志
- kube-proxy日志
- 应用程序日志
- 云原生:输出到控制台(/var/log/containers)
- 非云原生:输出到本地文件(容器内日志文件)
- 网关日志(如ingress-nginx)
- 服务之间调用链日志
1.2 日志收集常见的技术栈有哪些?¶
1.2.1 ELK架构¶
在传统架构中,比较成熟且流行的日志收集平台非ELK(Elasticsearch + Logstash + Kibana)莫属,其中Logstash负责采集日志,并输出至Elasticsearch,之后用Kibana进行展示。
缺点:
Logstash占用资源大,语法复杂
1.2.2 EFK架构¶
由于Logstash比较“重”,并且配置稍微有些复杂,所以出现了EFK的日志收集解决方案。相对于ELK中Logstash,Fluentd采用“一锅端”的形式,可以直接将某些日志文件中的内容存储至Elasticsearch,然后通过Kibana进行展示。其中Fluentd只能收集控制台日志(使用logs命令查出来的日志),不能收集非控制台日志,不能很好的满足生产环境的需求。大部分情况下,没有遵循云原生理念开发的程序,往往都会输出很多日志文件,这些容器内的日志无法采集,除非在每个Pod内添加一个Sidecar,将日志文件的内容进行tail -f转成控制台日志,但这也是非常麻烦的。
另外,用来存储日志的Elasticsearch集群是不建议搭建在Kubernetes集群中的,因为会非常浪费Kubernetes集群资源,所以大部分情况下通过Fluentd采集日志输出到外部的Elasticsearch集群中。
优点: Fluentd占用资源小,语法简单
缺点:
Fluentd只能收集控制台日志(使用logs命令查出来的日志),不能收集非控制台日志,不能很好的满足生产环境的需求;
依赖Elasticsearch,维护难度和资源使用都是偏高;

1、在k8s集群的每个node节点上起一个Fluentd的Pod,Fluentd配置一个类型为HostPath的volume,将宿主机的文件目录挂载到容器中。 2、Fluentd容器根据语法读到宿主机的日志文件。 3、Fluentd容器把读取到的日志文件打包给ES集群
1.2.3 Filebeat¶
在早期的ELK架构中,日志收集均以Logstash为主,Logstash负责收集和解析日志,它对内存、CPU、IO资源的消耗比较高,但是Filebeat所占系统的CPU和内存几乎可以忽略不计。
由于Filebeat本身是比较轻量级的日志采集工具,因此Filebeat经常被用于以Sidecar的形式配置在Pod中,用来采集容器内程序输出的自定义日志文件。当然,Filebeat同样可以采用DaemonSet的形式部署在Kubernetes集群中,用于采集系统日志和程序控制台输出的日志。至于Filebeat为什么采用DaemonSet的形式部署而不是采用Deployment和StatefulSet部署,原因有以下几点:
- 收集节点级别的日志:Filebeat需要能够访问并收集每个节点上的日志文件,包括系统级别的日志和容器日志。Deployment和STS的主要目标是部署和管理应用程序的Pod,而不是关注节点级别的日志收集。因此,使用DaemonSet更适合收集节点级别的日志
- 自动扩展:Deployment和STS旨在管理应用程序的副本数,并确保所需的Pod数目在故障恢复和水平扩展时保持一致。但对于Filebeat来说,并不需要根据负载或应用程序的副本数来调整Pod数量。Filebeat只需在每个节点上运行一个实例即可,因此使用DaemonSet可以更好地满足这个需求
- 高可用性:Deployment和STS提供了副本管理和故障恢复的机制,确保应用程序的高可用性。然而,对于Filebeat而言,它是作为一个日志收集代理来收集日志,不同于应用程序,其故障恢复的机制和需求通常不同。使用DaemonSet可以确保在每个节点上都有一个运行中的Filebeat实例,即使某些节点上的Filebeat Pod不可用,也能保持日志收集的连续性
Fluentd和Logstash可以将采集的日志输出到Elasticsearch集群,Filebeat同样可以将日志直接存储到Elasticsearch中,但是为了更好地分析日志或者减轻Elasticsearch的压力,一般都是将日志先输出到Kafka,再由Logstash进行简单的处理,最后输出到Elasticsearch中。
优点: 占用系统的CPU和内存小;
可以更好地分析日志;
缺点:
依赖Elasticsearch,维护难度和资源使用都是偏高;
Filebeat+Kafka+Logstash+ES架构解析:
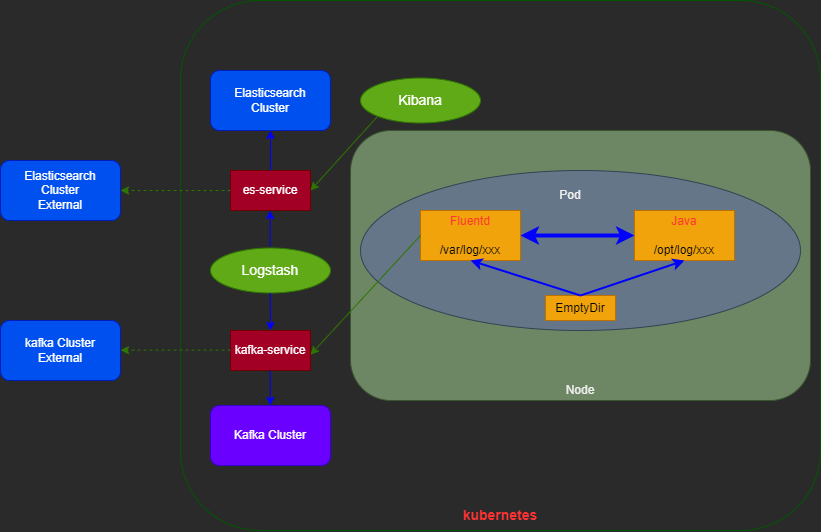
1.在k8s集群的每个pod都新起两个容器(Filebeat和应用容器-java),同时配置一个类型为EmptyDir的volume,将宿主机的文件目录挂载到两个容器中,达到日志共享目的。 2.Filebeat利用轻量级特性将日志文件打包给Kafka 3.Logstash获取到Kafka的日志信息,并进行解析。 4.解析完成后,数据存储到ES 5.Kibana从ES中查看日志数据
1.2.4 Loki¶
无论是ELK、EFK还是Filebeat,都需要用到Elasticsearch来存储数据,而Elasticsearch维护难度和资源使用都是偏高的。所以一个更轻量的日志收集平台-Loki应运而生。
Loki是Grafana Labs开源的一个支持水平扩展、高可用、多租户的日志聚合系统。

涉及如下组件:
- Loki:主服务器,负责日志的存储和查询,参考了Prometheus的服务发现机制,将标签添加到日志流,而不是像其他平台一样进行全文索引。
- Promtail:负责收集日志并将其发送给Loki,主要用于发现采集目标以及添加对应Label,最终发送给Loki。
- Grafana:用来展示或查询相关日志,可以在页面查询指定标签Pod的日志。
Loki不对日志进行全文索引,仅索引相关日志的元数据,所以Loki操作起来更简单、更省成本。而且Loki是基于Kubernetes进行设计的,可以很方便地部署在Kubernetes上,并且对集群的Pod进行日志采集,采集时会将Kubernetes集群中的一些元数据自动添加到日志中,让技术人员可以根据命名空间、标签等字段进行日志的过滤,可以很快速地定位到相关日志。
优点:
轻量化、操作简单、省成本
缺点:
相对其他技术栈功能不是很灵活
1.3 常见的日志收集工具对比¶
日志收集技术栈一般分为ELK,EFK,Filebeat,Loki。下面简单介绍这四种日志收集工具:
ELK是由Elasticsearch、Logstash、Kibana三者组成:
- Elasticsearch: Elasticsearch 是一个开源的分布式搜索和分析引擎。它可以用于存储和检索大量的结构化和非结构化数据,包括日志数据。Elasticsearch 提供了高性能、可伸缩性和全文搜索功能。
- Logstash: Logstash 是一个开源的数据收集、处理和传输工具。它可以从多种来源(如日志文件、消息队列等)收集数据,并对数据进行过滤、解析和转换,最终将数据发送到目标存储(如 Elasticsearch)。但是配置复杂、资源占用高
- Kibana: Kibana 是一个开源的数据可视化工具,用于分析和展示通过 Elasticsearch 存储的数据。Kibana 提供了强大的查询、图表、图形和仪表板功能,使用户可以实时监视和分析日志数据。
EFK是由Elasticsearch、Fluentd(Fluent-bit)、Kibana三者组成:
- Elasticsearch: Elasticsearch 是一个开源的分布式搜索和分析引擎。它可以用于存储和检索大量的结构化和非结构化数据,包括日志数据。Elasticsearch 提供了高性能、可伸缩性和全文搜索功能。
- Fluentd: Fluentd 是一个开源的日志收集器,用于统一收集、处理和传输日志数据。它可以从各种来源收集数据,并将其发送到目标存储(如 Elasticsearch)。Fluentd 支持灵活的插件系统,使用户可以根据自己的需求进行定制。但是配置复杂、资源占用高
- Fluent-bit:属于Fluentd的轻量级替代品,专为嵌入式系统和容器化环境设计。更加适用于资源受限的坏境如IoT设备、边缘计算节点等新工具、功能待完善。目前属于新工具、功能待完善
- Kibana: 是一个开源的数据可视化工具,用于分析和展示通过 Elasticsearch 存储的数据。Kibana 提供了强大的查询、图表、图形和仪表板功能,使用户可以实时监视和分析日志数据。
Filebeat 是一个轻量级的日志传输工具,由 Elastic 公司开发。它专门用于收集和发送日志数据到中央存储或分析系统,如 Elasticsearch 或 Logstash。Filebeat 可以监视指定的文件和位置,读取日志事件,并将其传输到指定的目的地。它支持多种日志格式和协议,并具有低资源消耗的特点。侧重于日志收集、不适合复杂的数据转换。
Loki 是一个开源的日志聚合系统,由 Grafana 实验室开发。它专注于存储、索引和查询日志数据。Loki 使用了流式处理和标签索引的方法,以实现高效的日志查询和分析。它与 Prometheus 集成紧密,并支持使用 Prometheus 的标签查询语言(PromQL)来查询和过滤日志数据。Loki 还提供了一组工具和库,用于日志收集和客户端端点的管理。
- Loki:主服务器,负责日志的存储和查询,参考了Prometheus的服务发现机制,将标签添加到日志流,而不是像其他平台一样进行全文索引。
- Promtail:负责收集日志并将其发送给Loki,主要用于发现采集目标以及添加对应Label,最终发送给Loki。
- Grafana:用来展示或查询相关日志,可以在页面查询指定标签Pod的日志。